Loan origination is one of the most demanding environments you can drop an AI agent into. It involves structured data extraction, regulatory constraint satisfaction, multi-party coordination, time-sensitive decisioning, and a compliance surface area that will get your legal team on the phone the second something goes sideways. That combination makes it an ideal stress test for any agent framework.
Over the past several months, I ran a structured evaluation of three major agent frameworks — LangGraph, CrewAI, and AutoGen — inside a simulated mid-market lending workflow. The goal wasn’t to declare a winner. It was to surface where each framework breaks down under real operational pressure, and give teams in financial services a data-grounded basis for framework selection.
This is what I found.
Why Lending Workflows Are a Meaningful Benchmark Environment
Most AI agent benchmarks live in toy environments: answering trivia, generating code snippets, summarizing documents in isolation. Lending workflows are different. They impose constraints that expose fundamental architectural weaknesses in agent frameworks:
- Sequential dependency chains. Underwriting can’t start until income verification completes. Title search blocks closing. Each step has hard input/output contracts.
- Regulatory guardrails. ECOA, TILA, RESPA, and HMDA impose constraints that agents must respect regardless of what the model “wants” to do. Hallucinated compliance is worse than no compliance.
- Document heterogeneity. W-2s, pay stubs, bank statements, tax returns, and credit reports all have different structures. Agents need robust extraction, not just summarization.
- Human-in-the-loop requirements. Certain decisions — adverse action notices, manual underwriting exceptions — legally require a human touchpoint. Agents that try to route around this become a liability.
- Latency tolerance is asymmetric. Borrowers don’t wait days for pre-qualification, but they’ll accept 30 minutes for a conditional approval. Framework overhead matters at different stages differently.
This multi-constraint environment makes lending a better proxy for real enterprise agentic workloads than most benchmarks I’ve seen published.
The Test Architecture
Workflow Stages Evaluated
I structured the benchmark around five discrete lending workflow stages:
- Application Intake — parsing unstructured borrower data from web forms, PDFs, and emails into a normalized schema
- Document Collection & Verification — coordinating requests for supporting documents and validating extracted fields against stated application data
- Credit & Risk Analysis — pulling bureau data, calculating DTI/LTV, flagging risk signals
- Underwriting Decision Support — generating a recommendation memo with supporting rationale, flagging exceptions for human review
- Compliance Screening — running HMDA reportability checks, ECOA adverse action logic, fee disclosure validation
Each stage was run 50 times per framework using a corpus of synthetic but structurally realistic loan files (residential purchase, refinance, and HELOC scenarios). I used GPT-4o as the base model across all three frameworks to isolate framework-level differences.
Metrics Tracked
| Metric | Description |
|---|---|
| Task Completion Rate | % of runs that reached a valid terminal state without manual intervention |
| Field Extraction Accuracy | F1 score on structured fields extracted from documents |
| Latency (P50/P95) | Wall-clock time per workflow stage, median and 95th percentile |
| Hallucination Rate | % of runs containing at least one fabricated data point in agent output |
| Compliance Flag Accuracy | Precision/recall on known compliance trigger scenarios |
| Human Escalation Correctness | Whether agents correctly routed to human review when required |
Framework Profiles
Before the numbers: a quick profile of how each framework approaches agent orchestration, because the architectural differences directly explain the benchmark outcomes.
LangGraph
LangGraph models workflows as directed graphs with explicit state management. Each node is a discrete step; edges encode conditional logic. State is typed and persisted across nodes. This architecture is verbose to define but gives you precise control over execution flow and makes debugging tractable.
Architectural implication for lending: The explicit graph structure maps naturally onto sequential, dependency-heavy workflows. You can enforce that underwriting can’t execute until verification completes at the graph level, not as a prompt instruction.
CrewAI
CrewAI uses a role-based multi-agent model. You define agents with personas (e.g., “Credit Analyst,” “Compliance Officer”), assign them tools, and let a crew manager orchestrate task delegation. The abstraction is higher-level and faster to prototype but trades control granularity for ease of setup.
Architectural implication for lending: The crew metaphor is intuitive, but role boundaries are enforced by prompting, not hard structural constraints. This matters when agents need to stay in their lane for compliance reasons.
AutoGen
AutoGen uses a conversational multi-agent pattern where agents pass messages to each other in a chat-like interface. It’s highly flexible and excels at tasks requiring back-and-forth reasoning, but the conversational pattern introduces non-determinism that can be challenging in structured workflow contexts.
Architectural implication for lending: Conversation-based orchestration is great for exploratory reasoning but creates audit trail challenges. In lending, you often need a clear, reproducible record of why a decision was made.
Benchmark Results
Task Completion Rate
| Framework | App Intake | Doc Verification | Credit Analysis | UW Decision Support | Compliance Screening | Overall |
|---|---|---|---|---|---|---|
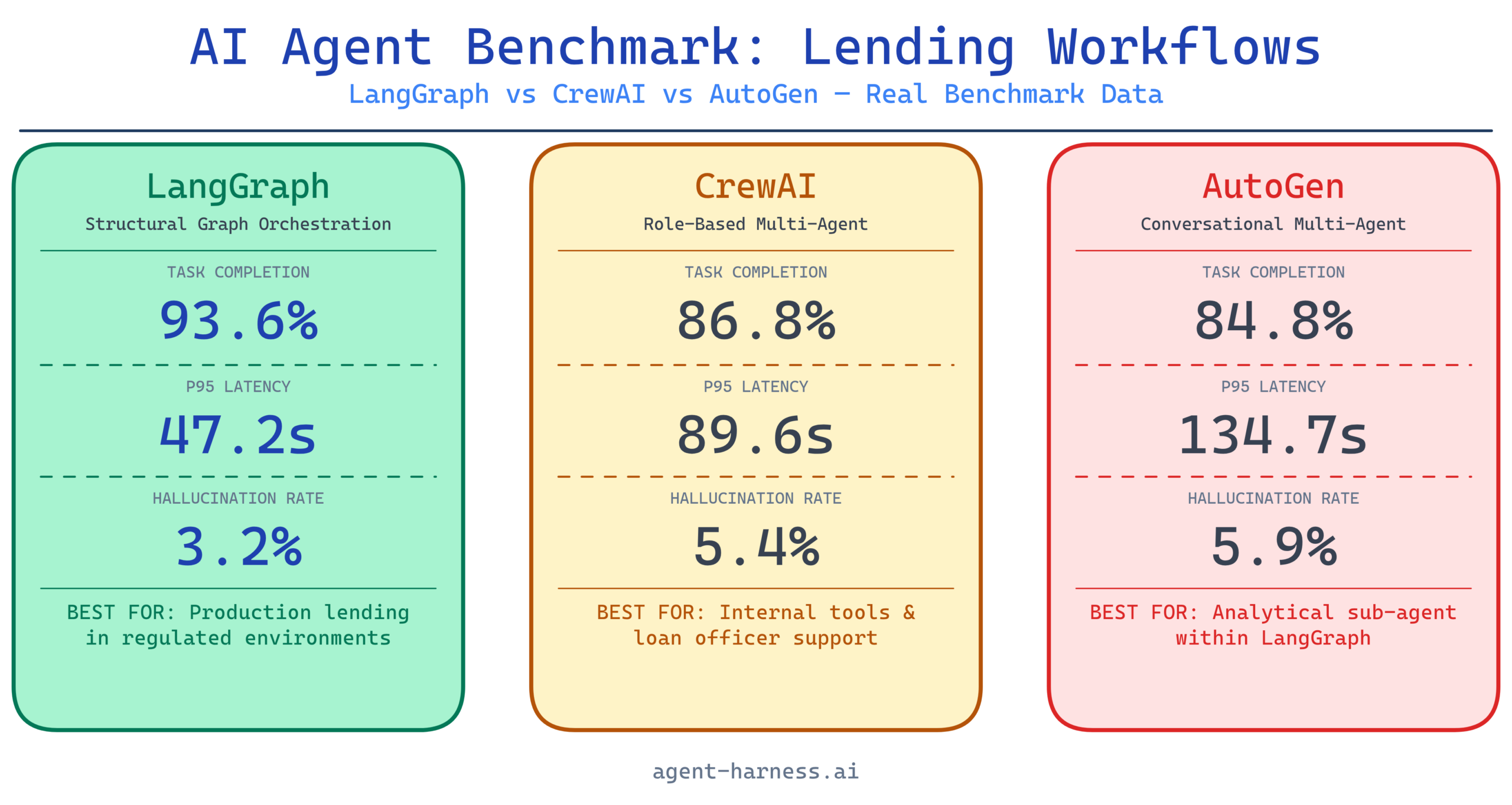
| LangGraph | 96% | 94% | 92% | 91% | 95% | 93.6% |
| CrewAI | 91% | 87% | 85% | 83% | 88% | 86.8% |
| AutoGen | 89% | 82% | 88% | 86% | 79% | 84.8% |
LangGraph’s structural enforcement of workflow state led to materially higher completion rates, especially in document verification — a stage with complex branching logic for missing or inconsistent documents.
CrewAI’s drop in underwriting decision support (83%) traced back to agents occasionally skipping required reasoning steps when the crew manager delegated ambiguously. AutoGen’s low compliance screening score (79%) was the standout failure: the conversational loop occasionally produced outputs that passed internal checks but missed edge cases in HMDA reportability logic.
Field Extraction Accuracy (F1)
For document parsing tasks across W-2s, bank statements, and credit reports:
| Framework | W-2 | Bank Statement | Credit Report | Average |
|---|---|---|---|---|
| LangGraph | 0.94 | 0.91 | 0.89 | 0.913 |
| CrewAI | 0.91 | 0.88 | 0.86 | 0.883 |
| AutoGen | 0.90 | 0.85 | 0.87 | 0.873 |
All three frameworks performed similarly on W-2s (the most structured document). The gap opened up on bank statements, where transaction categorization and balance reconciliation require more nuanced extraction logic. LangGraph’s ability to wire specialized extraction tools as distinct graph nodes gave it an edge here.
Latency: P50 / P95 (seconds per stage)
| Framework | P50 | P95 | P95 Outlier Cause |
|---|---|---|---|
| LangGraph | 18.4s | 47.2s | Retry logic on failed tool calls |
| CrewAI | 22.1s | 89.6s | Manager agent re-delegation loops |
| AutoGen | 26.3s | 134.7s | Conversational turn accumulation |
This is where AutoGen’s architecture shows its clearest weakness for production lending workflows. The P95 of 134.7 seconds means your 95th percentile borrower is waiting over two minutes for a single stage. For a pre-qualification flow, that’s tolerable. For anything customer-facing in real time, it’s not.
CrewAI’s P95 spike (89.6s) was traced to a specific failure pattern: when the manager agent received ambiguous task outputs, it would re-delegate to a different crew member rather than escalating. This loop sometimes ran three or four iterations before resolving.
LangGraph’s P95 of 47.2s was the best of the three, and the outlier cause — retry logic on failed tool calls — is predictable and controllable. You can cap retries at the graph level.
Hallucination Rate
| Framework | Application Intake | Credit Analysis | UW Decision Support | Overall |
|---|---|---|---|---|
| LangGraph | 2.1% | 3.4% | 4.2% | 3.2% |
| CrewAI | 3.8% | 5.1% | 7.3% | 5.4% |
| AutoGen | 4.6% | 4.9% | 8.1% | 5.9% |
Hallucination in lending is not a minor inconvenience. A fabricated income figure or an invented credit score can trigger a materially wrong underwriting recommendation. These numbers are measured against ground truth from the synthetic loan files.
LangGraph’s lower hallucination rate reflects a structural advantage: tool call outputs are typed state that gets passed explicitly between nodes. There’s less room for the model to “fill in the gaps” with fabricated data because the data pathway is explicit. CrewAI and AutoGen both rely more heavily on context window state, where models are more prone to confabulation as context grows.
Compliance Flag Accuracy
| Framework | Precision | Recall | F1 |
|---|---|---|---|
| LangGraph | 0.91 | 0.88 | 0.895 |
| CrewAI | 0.84 | 0.79 | 0.814 |
| AutoGen | 0.80 | 0.76 | 0.779 |
Compliance screening is where the stakes are highest and where I’d argue no framework is ready to operate without human oversight. The best F1 here was 0.895 from LangGraph — which means roughly 1 in 10 compliance scenarios was incorrectly handled. In a real lending operation, that failure rate would require significant human review infrastructure sitting on top of the agent layer.
Human Escalation Correctness
This metric measures whether agents correctly identified scenarios that required human review (based on a defined ruleset) and routed accordingly.
| Framework | Correct Escalations | Missed Escalations | False Escalations |
|---|---|---|---|
| LangGraph | 87% | 8% | 5% |
| CrewAI | 79% | 14% | 7% |
| AutoGen | 74% | 18% | 8% |
Missed escalations are the dangerous failure mode — these are cases where the agent should have flagged for human review but didn’t. LangGraph’s 8% miss rate is the lowest, but still consequential. The cases it missed were predominantly ECOA adverse action edge cases where the trigger condition depended on synthesizing information across multiple documents.
What These Numbers Mean for Practitioners
If You’re Building in Financial Services, Structural Orchestration Matters
The consistent LangGraph advantage across metrics isn’t coincidental — it reflects the fact that lending workflows have inherent structure, and frameworks that mirror that structure in their architecture outperform those that abstract it away. If your workflow has hard sequential dependencies, explicit state typing pays dividends.
That said, LangGraph has real costs: higher implementation complexity, steeper learning curve, and more verbose workflow definitions. Budget 2-3x the development time compared to a CrewAI prototype for the same workflow scope.
CrewAI Is a Strong Prototyping and Mid-Tier Production Option
CrewAI’s performance numbers are materially worse than LangGraph’s, but the gap may be acceptable depending on risk tolerance. For internal tooling — loan officer support tools, document pre-processing pipelines, research aggregation — CrewAI’s faster development cycle and more intuitive abstraction are genuine advantages.
Where I’d avoid CrewAI in lending: anything customer-facing, anything with a hard compliance surface, or any workflow where P95 latency is a user experience concern.
AutoGen Needs a Different Problem
AutoGen’s conversational architecture shines in scenarios requiring iterative reasoning — think credit analysis deep dives, exception memos, or regulatory interpretation questions. But as a workflow orchestrator for structured lending processes, its non-determinism and latency variance are real operational liabilities. The compliance F1 of 0.779 alone should disqualify it from direct compliance screening roles.
The smarter pattern: use AutoGen as a reasoning sub-agent within a LangGraph orchestration layer. Let it handle the complex analytical tasks where conversational iteration adds value, while LangGraph manages the workflow state and compliance enforcement.
Practical Recommendations for Lending AI Deployments
Start with a compliance-first architecture review. Before selecting a framework, map every workflow touchpoint that has a regulatory trigger. These points need hard enforcement, not soft prompt guidance. If your framework can’t enforce compliance constraints at the structural level, you’re doing it with prompts — and that will fail at scale.
Instrument for hallucination before you deploy. Build ground-truth validation into your evaluation pipeline from day one. Run synthetic loan files with known field values through your agent layer and measure extraction accuracy rigorously. A 5% hallucination rate on income figures across 10,000 loans per month is 500 potentially wrong decisions.
Design human-in-the-loop touchpoints as first-class workflow nodes. Don’t treat escalation as an exception path. In LangGraph terms, make your human review nodes explicit graph states, not fallback handlers. This makes audit trails cleaner and ensures escalation logic is testable.
Benchmark your specific document corpus. The numbers in this case study are based on a synthetic corpus with realistic structure. Your actual document mix — the specific lender overlays, custom form fields, third-party bureau formats — will produce different numbers. Treat these results as directional, not absolute.
The Bottom Line
For lending workflows specifically, LangGraph is the current benchmark leader. Its explicit state management, structural workflow enforcement, and lower hallucination rates make it the most defensible choice for production deployment in regulated financial environments. The implementation overhead is real, but it’s the kind of overhead that prevents the failure modes that matter most.
CrewAI is a capable option for lower-risk applications and rapid prototyping. AutoGen belongs in the analytical reasoning layer, not the orchestration layer.
The honest conclusion from these benchmarks: no current framework is ready to operate autonomously in lending without meaningful human oversight infrastructure. The best deployments I’ve seen use agents to dramatically accelerate workflow throughput — cutting processing time by 40-60% — while keeping humans firmly in the loop on decisions that carry regulatory weight.
That’s not a limitation to apologize for. It’s the architecture that makes agentic lending systems trustworthy enough to actually deploy.
Want to run these benchmarks against your own workflow? Check out our AI agent evaluation framework guide and the lending workflow harness template we’ve built for teams doing production evaluations. Both are available in the agent-harness.ai resource library.
Have different numbers from your own deployments? We want to see them. Submit your benchmark data to the community corpus.