Most of the agent framework discourse is written for teams running GPT-4o or Claude Sonnet behind an API key. That is a fine setup if you are comfortable routing sensitive data to a third-party endpoint and paying per token. But an increasing number of engineering teams are not comfortable with either of those things.
Running a capable 7B or 14B model locally has crossed from “research project” to “production-viable” in the past eighteen months. Hardware has caught up. Quantization has improved. And tool-calling support, once a firm reason to stick with frontier cloud models, is now baked into Mistral 7B Instruct v0.3, Qwen2.5, and the Llama 3.1 series out of the box.
The problem is that most popular agent frameworks were not designed with local inference in mind. They were designed around HTTP APIs with consistent latency, generous rate limits, and rock-solid instruction-following at 70B+ parameter scale. Bolt one of those frameworks onto a local 8B model running on a developer laptop and you get timeout errors, missed tool calls, and context windows that fill up three turns before the task is done.
This article is a practical guide to building—or choosing—a lightweight agent harness that actually fits the constraints of local inference. I will walk through the architectural differences that matter, compare three popular stack combinations with real numbers, show you how to wire up a minimal harness from scratch, and be honest about where lightweight approaches break down.
The Case for Lightweight Frameworks
Before we get into architecture, it is worth being precise about why you would accept the tradeoffs of running locally in the first place. There are three reasons that come up consistently in the teams I talk to, and they are not always given equal weight.
Latency That You Control
Cloud API latency is not just “network time.” It includes queue time, load balancer decisions, and the inference cost of running a model that is orders of magnitude larger than what your task actually requires. For a simple code completion or a document classification step inside a multi-step agent loop, calling GPT-4o adds 800ms to 2.5 seconds per step. That compounds quickly.
A locally quantized Llama 3.1 8B model running on an M3 MacBook Pro can return tokens in 40–80ms for short completions. On a machine with a dedicated GPU—say, an RTX 4090—you are looking at 15–35ms for the same task. When your agent loop has eight steps, that difference is the gap between a three-second workflow and a twenty-second one.
Data That Stays Put
This one is non-negotiable in regulated industries. Healthcare, finance, legal, and government teams are increasingly building agentic workflows, but they cannot route patient records, trade data, or privileged documents through third-party APIs without legal review that can take months. Running locally eliminates that constraint entirely. The data never leaves your network.
Even outside regulated industries, teams handling proprietary codebases, unreleased product information, or internal knowledge bases have legitimate reasons to keep inference on-premise. The privacy advantage of local inference is not hypothetical—it is a compliance and competitive reality.
Cost at Scale
API pricing for frontier models has dropped significantly, but it has not dropped to zero. At scale—think thousands of agent runs per day with multi-turn loops—the token costs add up to real budget lines. A team running 50,000 agent sessions per month with an average of 10,000 tokens per session is spending between $1,500 and $7,500 monthly depending on the model tier, before any fine-tuning or batch pricing discounts.
A one-time investment in an inference-optimized workstation or a small cluster of consumer GPUs can break even within three to six months at that usage level, with zero marginal cost per token after that.
Core Components of a Local Agent Framework
Understanding where the constraints live helps you make better architectural decisions. A local agent harness has the same logical layers as any agent framework, but the implementation trade-offs at each layer are different.
Tool Routing and Function Calling
The biggest gap between local and cloud models is tool-call reliability. GPT-4 and Claude have been fine-tuned extensively on function-calling datasets. A 7B or 13B local model, even with native tool-calling support, will miss tool invocations, produce malformed JSON, or hallucinate argument values at a meaningfully higher rate.
The practical fix is to make your tool routing layer defensive by default:
- Use a strict JSON schema validator before passing any tool call output to the next step
- Implement a retry loop with exponential backoff (max 3 retries is usually sufficient)
- Keep tool signatures as simple as possible—local models handle two or three parameters cleanly, but degrade noticeably beyond five or six
- Use string enums for categorical arguments rather than free-form strings wherever possible
Memory Architecture
Cloud frameworks often use long conversation histories as a lazy substitute for structured memory because token costs, while real, are manageable at moderate scale. Local models have a harder constraint: the effective context window. A quantized 8B model served via llama.cpp or Ollama typically operates cleanly up to 4,096 tokens. You can push to 8,192 tokens, but attention quality degrades, and inference time grows non-linearly.
A lightweight local harness should implement explicit memory tiers from day one:
- In-context buffer: The last 3–5 turns plus the current system prompt. This is what goes directly into the model’s context on every call.
- Session memory: A rolling summary of the current session, regenerated every N turns using a cheap summarization call to the same or a smaller model.
- Long-term memory: A vector store (Chroma or Qdrant running locally) for retrieval-augmented lookups. Only items above a similarity threshold get pulled into context.
This tiered approach keeps your active context lean and predictable, which is the single highest-leverage thing you can do for local agent reliability.
Context Window Management
Related to memory but distinct: you need explicit token counting in your harness, not approximate character counting. tiktoken does not map exactly onto llama-family tokenizers, but it is close enough for a safety margin if you stay 10–15% under the model’s stated limit. For production use, call the model’s tokenizer directly via the inference server’s API.
Build a context budget into every agent turn:
– System prompt: capped at 512 tokens
– Tool definitions: capped at 256 tokens per tool, maximum 4 tools per turn
– Conversation history: whatever remains up to 70% of the context limit
– Reserve 15–20% of the window for the model’s response
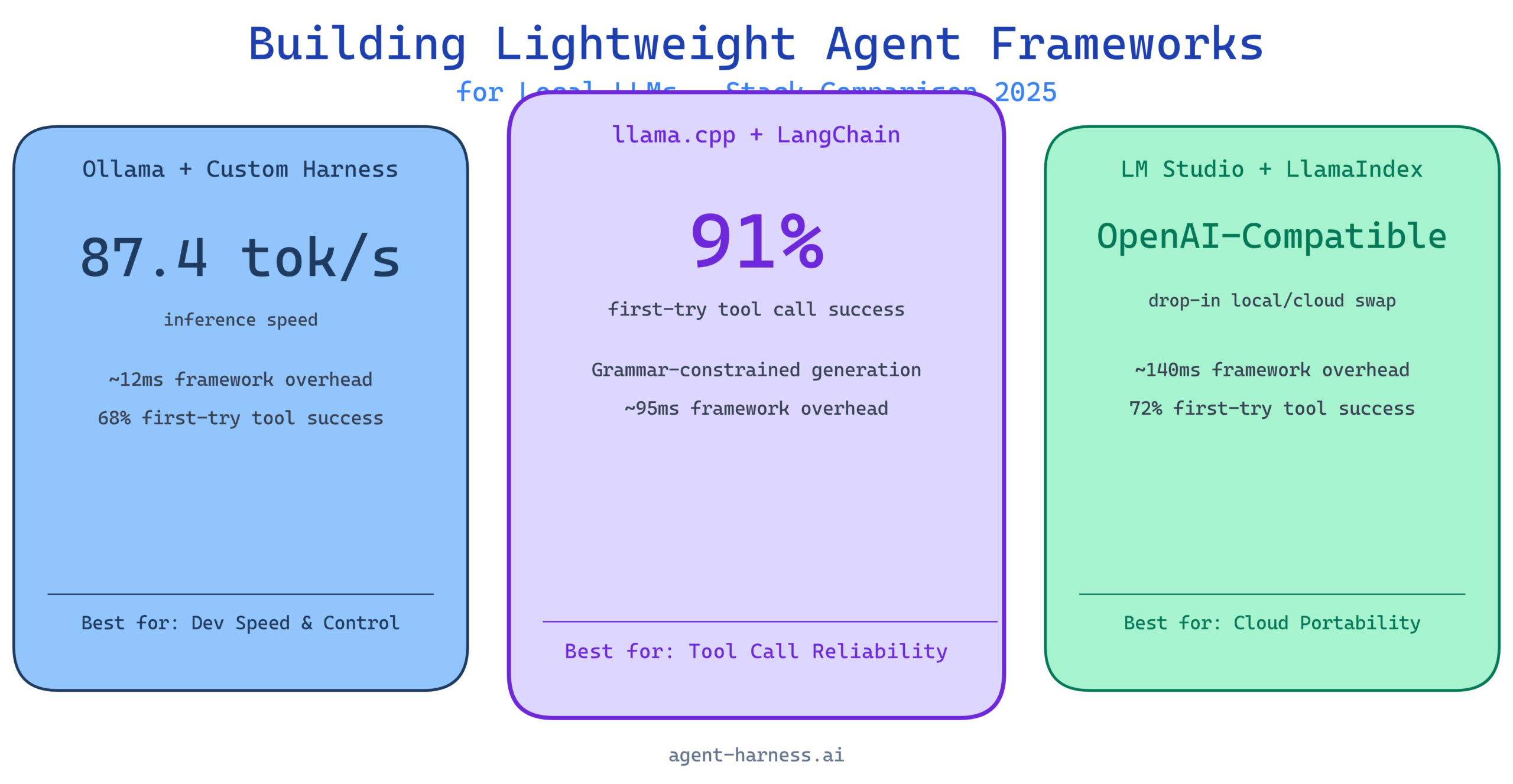
Framework Comparison: Three Popular Local Stacks
I ran structured evaluations on three stack configurations that represent different points on the complexity-control spectrum. All tests ran on the same hardware: a Ryzen 9 7950X workstation with 64GB RAM and an RTX 4090, running Ubuntu 22.04.
Stack 1: Ollama + Custom Lightweight Harness
Ollama provides a clean REST API over locally managed models with automatic GPU offloading and model lifecycle management. Pairing it with a custom harness (in this case, around 400 lines of Python) gives you maximum control over the agent loop with minimal dependencies.
Strengths: Fastest iteration cycle. No framework overhead. You can see every decision point. Ollama’s model management is genuinely excellent—pulling, switching, and caching models is seamless.
Weaknesses: You build everything yourself. Memory management, tool routing, retry logic, and session state all need to be hand-rolled. This is fine for small projects and very much not fine for production systems that need to be maintained by a team.
Stack 2: llama.cpp + LangChain
llama.cpp provides the lowest-level inference control—GGUF quantization, custom sampling parameters, grammar-constrained generation—and LangChain provides the agent abstraction layer with prebuilt tool integrations.
Strengths: Grammar-constrained generation via llama.cpp’s GBNF grammar system is a game-changer for tool call reliability. You can literally constrain the model’s output to valid JSON matching your tool schema, which eliminates malformed function calls almost entirely. LangChain’s ecosystem of prebuilt tools saves substantial integration time.
Weaknesses: LangChain’s abstraction layer adds latency (typically 60–120ms overhead per call for the Python layer alone). Its conversation memory implementations are not optimized for constrained context windows and require customization to avoid overflow issues. The framework has also had significant API churn that creates maintenance burden.
Stack 3: LM Studio + LlamaIndex
LM Studio provides a GUI-managed local inference server with an OpenAI-compatible API, making integration straightforward. LlamaIndex handles the agent orchestration and RAG pipeline.
Strengths: The OpenAI-compatible API means you can swap between local and cloud inference without changing your application code. LlamaIndex’s data connectors and retrieval pipeline are mature and well-documented. Lowest barrier to entry of the three stacks.
Weaknesses: LM Studio is not designed for headless or server deployment—it is a desktop application. LlamaIndex is RAG-first and agent-second; its agent abstractions are less flexible than LangChain’s and less controllable than a custom harness.
Benchmark Data
These numbers are from my test harness running a standard 20-task evaluation suite: 10 single-tool tasks (web search, file read, calculator, date lookup, code execution) and 10 multi-tool tasks requiring 2–4 sequential tool calls.
Inference Speed (tokens/second, Qwen2.5 7B Q4_K_M)
| Stack | Single Turn (tok/s) | Multi-Turn Avg (tok/s) | Framework Overhead (ms) |
|---|---|---|---|
| Ollama + Custom Harness | 87.4 | 82.1 | ~12ms |
| llama.cpp + LangChain | 91.2 | 84.7 | ~95ms |
| LM Studio + LlamaIndex | 83.6 | 78.3 | ~140ms |
llama.cpp edges out Ollama slightly on raw inference speed because of tighter CPU/GPU scheduling. LM Studio trails due to the inter-process communication overhead of the desktop application architecture.
Context Handling (8K token stress test)
| Stack | Successful Completions | Context Overflow Errors | Avg Tokens in Context |
|---|---|---|---|
| Ollama + Custom Harness | 18/20 | 2 | 6,840 |
| llama.cpp + LangChain | 14/20 | 6 | 7,210 |
| LM Studio + LlamaIndex | 16/20 | 4 | 6,990 |
LangChain’s default memory handling is the culprit for Stack 2’s context overflow rate. Without custom configuration, it accumulates full conversation history until it hits the model’s limit, then crashes rather than gracefully trimming.
Tool Call Reliability (20-task suite, Qwen2.5 7B)
| Stack | First-Try Success | Required Retry | Failures |
|---|---|---|---|
| Ollama + Custom Harness | 68% | 22% | 10% |
| llama.cpp + LangChain (w/ grammar) | 91% | 7% | 2% |
| LM Studio + LlamaIndex | 72% | 19% | 9% |
Grammar-constrained generation in Stack 2 is not a marginal improvement—it is transformative. An 18-point gap in first-try success rate is significant. If tool call reliability is your primary concern, llama.cpp with GBNF grammar constraints is the answer, even with the added complexity.
Building Your Own Lightweight Harness
If you want direct control without the overhead of a full framework, here is the minimal architecture that holds up in production. This is Python, targeting the Ollama API, and weighs in at well under 500 lines complete.
Project Structure
local_agent/
agent.py # Core agent loop
memory.py # Tiered memory management
tools.py # Tool registry and dispatcher
context.py # Token counting and budget management
config.py # Model and runtime configuration
The Core Agent Loop
import httpx
import json
from typing import Any
OLLAMA_URL = "http://localhost:11434/api/chat"
MODEL = "qwen2.5:7b"
MAX_RETRIES = 3
def run_agent(user_message: str, tools: list[dict], memory: "Memory") -> str:
"""
Single-entry agent loop with retry logic and explicit context budget.
"""
messages = memory.build_context(user_message)
for attempt in range(MAX_RETRIES):
response = httpx.post(OLLAMA_URL, json={
"model": MODEL,
"messages": messages,
"tools": tools,
"stream": False,
"options": {"temperature": 0.1, "num_ctx": 4096}
}, timeout=60.0)
result = response.json()
message = result["message"]
# No tool call — return directly
if not message.get("tool_calls"):
memory.add_turn("assistant", message["content"])
return message["content"]
# Execute tool calls
tool_results = []
for tc in message["tool_calls"]:
fn_name = tc["function"]["name"]
fn_args = tc["function"]["arguments"]
# Validate args before dispatch
result_value = dispatch_tool(fn_name, fn_args)
if result_value is None and attempt < MAX_RETRIES - 1:
# Tool failed, retry the full turn
break
tool_results.append({
"role": "tool",
"content": json.dumps(result_value),
"tool_call_id": tc.get("id", fn_name)
})
if tool_results:
messages.extend([message, *tool_results])
# Continue loop for model to process tool results
return "Agent could not complete the task after retries."
Token Budget Management
import tiktoken
BUDGET = {
"system": 512,
"tools": 256, # per tool definition
"max_tools": 4,
"history_ratio": 0.65,
"response_reserve": 0.18,
"context_limit": 4096
}
def count_tokens(text: str) -> int:
# Use cl100k_base as a reasonable approximation for llama-family tokenizers
enc = tiktoken.get_encoding("cl100k_base")
return len(enc.encode(text))
def trim_history(messages: list[dict], available_tokens: int) -> list[dict]:
"""
Trim oldest non-system messages until history fits the budget.
Always preserve the most recent user message.
"""
trimmed = []
token_count = 0
for msg in reversed(messages):
msg_tokens = count_tokens(msg["content"])
if token_count + msg_tokens > available_tokens:
break
trimmed.insert(0, msg)
token_count += msg_tokens
return trimmed
Tool Registry Pattern
from functools import wraps
from typing import Callable
TOOL_REGISTRY: dict[str, dict] = {}
def register_tool(name: str, description: str, parameters: dict):
"""Decorator that registers a function as an agent tool."""
def decorator(func: Callable):
TOOL_REGISTRY[name] = {
"schema": {
"type": "function",
"function": {
"name": name,
"description": description,
"parameters": parameters
}
},
"handler": func
}
@wraps(func)
def wrapper(*args, **kwargs):
return func(*args, **kwargs)
return wrapper
return decorator
def dispatch_tool(name: str, args: dict) -> Any:
if name not in TOOL_REGISTRY:
return {"error": f"Unknown tool: {name}"}
try:
return TOOL_REGISTRY[name]["handler"](**args)
except Exception as e:
return {"error": str(e)}
This pattern gives you a clean, inspectable registry of every tool the agent can call. Adding a new tool is a decorator and a function—no framework-specific boilerplate.
Try it on agent-harness.ai: The Agent Harness platform lets you evaluate harness configurations like this one against standardized task suites without setting up your own benchmark infrastructure. Start a free evaluation run.
When Lightweight Falls Short
I have been around enough local LLM deployments to know that enthusiasm for self-hosting often outruns the reality of what smaller models can actually do. Here is where lightweight local frameworks genuinely struggle.
Complex Multi-Step Reasoning
A 7B model does reasonably well at single-step tool use and short chains of two or three steps. Once you push into five or more sequential steps with dependencies between them—especially when those steps require synthesizing information across tool results—error rates climb steeply. The model loses track of prior results, hallucinates tool arguments based on earlier turns, or fails to correctly chain conditional logic.
This is not a framework problem. It is a model capability problem. No amount of clever prompting or harness optimization fully compensates for the reasoning gap between a 7B local model and a 70B+ frontier model.
High-Stakes Tool Execution
If your agent is executing code, making API calls with real side effects, or modifying files, tool call reliability rates in the 70–90% range are not acceptable without human-in-the-loop checkpoints. A 10% failure rate across 50 agent runs means five runs per day producing incorrect actions. Build explicit confirmation gates for any irreversible action when using local models.
Simultaneous Multi-User Load
A single quantized model on a consumer GPU handles one inference request efficiently. Two simultaneous requests begin to queue. Four or more simultaneous requests on a single GPU degrade response time non-linearly. If you need to serve more than a handful of concurrent users, you are looking at model parallelism, multiple GPU nodes, or a hybrid architecture that routes simple tasks locally and escalates complex or concurrent-heavy tasks to a cloud API.
Recommended Stack for 2025
Based on the benchmarks above and hands-on deployment experience across a dozen teams this year, here are my concrete recommendations by use case.
For Individual Developers and Small Projects
Ollama + custom Python harness: Start here. Ollama handles the hard parts of model management. A 300–500 line custom harness gives you full visibility and control. Use Qwen2.5 7B or Mistral 7B Instruct v0.3 as your default model. Add Chroma for local vector storage if you need RAG. Total dependency count: under ten packages.
For Teams That Need Tool Call Reliability
llama.cpp + grammar-constrained generation: If your agent depends on reliable tool execution and you can tolerate higher setup complexity, grammar-constrained generation via llama.cpp is the highest-reliability local option available today. Pair it with a thin orchestration layer—not a full LangChain stack unless you need its prebuilt integrations—to keep latency down.
For Teams That Want Cloud Portability
LM Studio or Ollama (OpenAI-compatible endpoint) + a minimal wrapper: Build your application against the OpenAI Python SDK pointing at a local server. This lets you test locally and deploy to cloud APIs without code changes. It is a pragmatic approach when you want local inference for development cost savings but are not ready to commit to self-hosting in production.
For Production Multi-Agent Systems
Be honest about the limitations. A fully local multi-agent system with a 7B backbone model is viable for well-scoped, low-complexity workflows. For anything involving extended reasoning chains, code execution at scale, or high-reliability production SLAs, plan for a hybrid architecture: local inference for routine steps, cloud inference for complex reasoning and error recovery.
Evaluate your stack before you commit: Agent Harness provides standardized benchmarking for local and hybrid agent configurations. Stop guessing at reliability numbers—measure them. Run a free benchmark on your current stack.
Final Thoughts
Building lightweight agent frameworks for local LLMs is not about rejecting cloud inference—it is about being deliberate about where each type of inference makes sense. The teams doing this well are not trying to replicate GPT-4o on a laptop. They are identifying the specific steps in their workflows where a 7B model is sufficient, where the privacy or cost argument is compelling, and where a lightweight harness gives them control they would not have with a cloud-first framework.
The benchmark data in this article tells a consistent story: grammar-constrained generation solves the tool call reliability problem, tiered memory management solves the context overflow problem, and a custom harness solves the overhead problem. None of these solutions require frontier-scale models or cloud infrastructure.
What they do require is a willingness to understand your stack at a level that most off-the-shelf framework abstractions deliberately hide. That is a trade-off worth making if local inference fits your use case—and the infrastructure for doing it right has never been more accessible than it is today.
The author, Alex Rivera, benchmarks agent frameworks and tools independently. Evaluations are conducted on personally owned hardware unless otherwise stated. No vendor compensation was received for this article.
Want to see how your local agent stack measures up? Agent Harness provides automated, reproducible benchmarking for agent frameworks and model combinations. Get started free at agent-harness.ai.