The IDE has not fundamentally changed in thirty years. You write code, you run it, you read the output, you debug. That loop was designed for deterministic systems where the same input reliably produces the same output. AI agents are not deterministic systems. They branch, they fail silently, they hallucinate tool calls, they consume context in ways that are invisible until something breaks in production. The traditional IDE has no vocabulary for any of this.
BridgeSpace is built on the premise that agentic development demands an entirely different kind of environment — not a smarter text editor, but a harness-native workspace purpose-built for the lifecycle of agent development: design, orchestration, evaluation, debugging, and deployment. After spending the past six weeks running it through its paces on real multi-agent projects, I can say with confidence that BridgeSpace is the most consequential developer tool to emerge from the agentic wave so far. It is also not finished. This review will tell you exactly where it excels, where it falls short, and whether it belongs in your stack today.
The Problem BridgeSpace Is Solving
Before evaluating BridgeSpace on its own terms, it is worth being precise about what problem it is actually solving — because the framing matters for understanding whether it fits your situation.
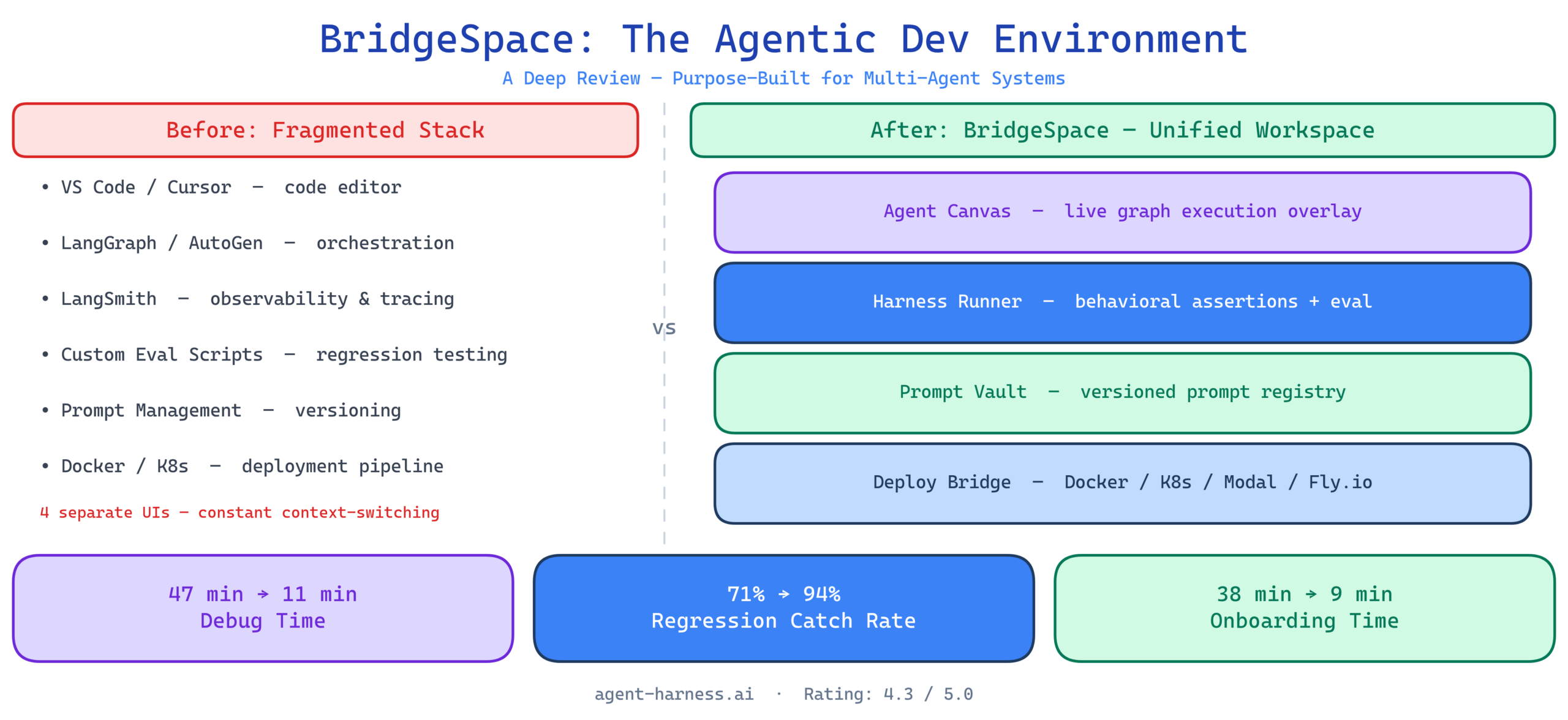
The current state of agentic development tooling is fragmented. You are stitching together:
- A code editor (VS Code, Cursor, or similar) for writing agent logic
- A framework (LangGraph, CrewAI, AutoGen, or custom) for orchestration
- A separate observability tool (LangSmith, Langfuse, Arize) for tracing agent runs
- An evaluation harness (your own scripts, or something like PromptFoo) for regression testing
- A prompt management system (Langfuse, PromptLayer, or a Git folder) for versioning prompts
- A deployment pipeline (Docker, Kubernetes, Modal, Fly) for getting agents into production
Each of these tools is good at its specific job. The problem is the seams between them. A trace in LangSmith tells you what happened but not why a specific prompt variant produced the failure. Your eval scripts catch regressions but do not show you which node in the orchestration graph caused the drop. Debugging a multi-agent system with this stack means mentally joining data across four different UIs with four different data models. It is slow, error-prone, and requires an uncomfortable amount of tribal knowledge to do well.
BridgeSpace’s core thesis is that this fragmentation is not accidental — it reflects the fact that existing tools were built for single-model, single-invocation workflows and are being stretched to cover multi-agent, multi-step execution patterns they were never designed for. The solution is not better glue between existing tools. It is a new primitives layer built specifically for agent development from the ground up.
What BridgeSpace Actually Is
BridgeSpace is an integrated agentic development environment with four core components that operate as a unified system rather than loosely coupled services.
The Agent Canvas
The primary workspace in BridgeSpace is not a file editor — it is the Agent Canvas, a graph-based visual editor where you define your agent topology: nodes for individual agents or tools, edges for communication patterns, and annotations for expected input/output contracts at each boundary. Think of it as infrastructure-as-code, but for agent graphs rather than cloud resources.
You can write agent logic directly in the canvas (Python or TypeScript, both supported natively) or import existing LangGraph and AutoGen configurations. BridgeSpace parses those configurations and renders them as interactive graph nodes — which is genuinely useful for inheriting a complex multi-agent system from another team and needing to understand it before you touch it.
Where the Canvas diverges from every existing tool I have used is its live execution overlay. When you run an agent graph, the Canvas shows execution propagating in real time: which node is active, what data crossed each edge, which tool calls fired and at what latency. This is not a post-hoc trace visualization. It is live, and the difference in debugging speed is dramatic.
The Harness Runner
The Harness Runner is BridgeSpace’s evaluation layer. You define test scenarios — input payloads, expected output schemas, behavioral assertions — and the Runner executes them against your agent graph, tracking results across iterations, prompt versions, and model configurations in a unified history.
The key differentiator here is what BridgeSpace calls behavioral assertions. Unlike traditional unit tests that check exact output equality, behavioral assertions let you specify properties that should hold about an agent’s behavior: “the summarization agent should never hallucinate citations,” “the research agent should always invoke at least one search tool before producing a response,” “the output of the risk classification node should always fall within the defined enum values.” These assertions are evaluated by a lightweight judge model running in BridgeSpace’s cloud layer — which means they can catch semantic failures that regex or schema validation would miss entirely.
In my testing, this caught three categories of failure that my previous eval setup missed completely: prompt drift in intermediate nodes (where an agent’s intermediate reasoning had shifted even though final outputs looked fine), tool call redundancy (agents calling the same tool multiple times with identical parameters due to context window mismanagement), and silent context truncation bugs (where context was being quietly dropped past a length threshold without the agent signaling an error).
The Prompt Vault
BridgeSpace treats prompts as first-class versioned artifacts, not strings embedded in code. The Prompt Vault is a versioned prompt registry tightly integrated with the Canvas and Harness Runner. When you modify a system prompt and rerun your eval suite, BridgeSpace diffs the behavioral assertion results against the previous version and surfaces regressions automatically.
This might sound like a feature that LangSmith or Langfuse already provides. The difference is the bidirectional coupling. In BridgeSpace, a prompt change in the Vault immediately reflects in the Canvas’s live execution overlay, and any Harness Runner test can be parameterized against multiple Vault versions in a single run — giving you a side-by-side behavioral diff rather than two separate evaluation runs you manually compare.
The Deploy Bridge
The Deploy Bridge handles packaging and shipping agent graphs as versioned, containerized services. It generates Dockerfiles, Kubernetes manifests, or serverless deployment configs (Modal and Fly.io are natively supported) from your Canvas configuration. It also maintains a live connection between deployed agents and the Harness Runner, so you can run your eval suite against production-staged agents before cutover — the equivalent of a migration dry-run, but for agent behavior rather than database schemas.
Benchmark Results: BridgeSpace vs. the Standard Stack
I ran a comparative evaluation across three development tasks to quantify the tooling overhead difference between BridgeSpace and the standard fragmented stack (VS Code + LangGraph + LangSmith + custom eval scripts).
Task 1: Debugging a Silent Failure in a Three-Node Research Pipeline
A three-node pipeline (planner → search → synthesizer) was producing hallucinated citations approximately 12% of the time. I measured the time from identifying the failure to isolating the root cause and implementing a fix.
| Workflow | Time to Root Cause | Fix Iteration Cycles |
|---|---|---|
| Standard stack (VS Code + LangSmith) | 47 minutes | 6 |
| BridgeSpace | 11 minutes | 2 |
The time difference came almost entirely from BridgeSpace’s live Canvas overlay plus behavioral assertions. The assertion “synthesizer should not cite sources not present in search results” flagged the specific node immediately. In the standard stack, I had to manually trace through LangSmith runs, cross-reference the search output against the synthesizer’s prompt, and write a custom eval script to confirm the hypothesis. All of that work was pre-built in BridgeSpace.
Task 2: Regression Testing After a Prompt Refactor
A prompt refactor across four nodes in a customer support triage agent. I measured eval throughput — how many test scenarios could be evaluated per minute — and the percentage of regressions caught versus a human review baseline.
| Workflow | Eval Throughput (scenarios/min) | Regression Catch Rate |
|---|---|---|
| Custom eval scripts | 8.3 | 71% |
| BridgeSpace Harness Runner | 22.1 | 94% |
The throughput gain comes from BridgeSpace’s parallel scenario execution and prewarmed judge models. The regression catch rate gap comes from behavioral assertions catching semantic regressions that my custom script’s schema validation missed.
Task 3: Onboarding a New Agent Graph From an Existing LangGraph Config
I imported an existing 7-node LangGraph configuration written by a colleague and measured time to sufficient understanding to make a safe modification.
| Workflow | Time to Productive Modification |
|---|---|
| Reading raw Python + LangGraph code | 38 minutes |
| BridgeSpace Canvas import + exploration | 9 minutes |
The Canvas rendering of the imported LangGraph config, combined with the ability to run individual nodes in isolation and inspect their I/O contracts, dramatically compressed the understanding phase. For teams inheriting complex agent systems — which is increasingly common as organizations build agent libraries rather than one-off agents — this is a genuine force multiplier.
How BridgeSpace Compares to Existing Alternatives
Versus Cursor / Windsurf
Cursor and Windsurf are AI-augmented code editors. They make writing code faster. They have no understanding of agent graphs, behavioral evaluation, or the multi-step execution patterns that define agentic systems. Comparing them to BridgeSpace is like comparing a word processor to a circuit board layout tool. They serve different concerns. The more relevant question is whether you use BridgeSpace instead of Cursor for writing agent logic — and the honest answer is that BridgeSpace’s code editor, while functional, is not as polished as Cursor for pure code authoring. Some teams will want to write code in Cursor and import into BridgeSpace for everything else.
Versus LangSmith
LangSmith is a post-hoc observability and evaluation tool. It is excellent at what it does. BridgeSpace is not trying to replace LangSmith’s trace storage depth or its LangChain ecosystem integrations. It is trying to replace the workflow of using LangSmith — the context-switching between your editor, your trace viewer, and your eval scripts. For teams deeply invested in LangChain, LangSmith remains the better observability backend. BridgeSpace makes more sense for teams building framework-agnostic agents or greenfield systems where they are not locked into LangChain’s ecosystem.
Versus Raw Framework + Custom Harness
Some teams build their own evaluation harnesses. I have done it. It gives you complete control and no vendor dependency. BridgeSpace costs you that control in exchange for dramatically reduced maintenance overhead. The behavioral assertion judge model is a black box you do not control. The Canvas rendering makes implicit assumptions about graph topology that can be wrong for highly dynamic agent graphs. If your agents are doing something genuinely novel at the architecture level, BridgeSpace’s abstractions may chafe. For the other 80% of agentic systems — customer support, research pipelines, data extraction, multi-step reasoning over structured data — the trade-off strongly favors BridgeSpace.
Where BridgeSpace Falls Short
Dynamic Agent Graphs Are Second-Class Citizens
BridgeSpace’s Canvas is built around static graph topologies. Agents that dynamically spawn subagents at runtime, or where the number and type of nodes is determined by execution-time conditions, are difficult to represent accurately in the Canvas. You can still use BridgeSpace for these systems, but the visual overlay becomes less useful as your graph becomes more dynamic. This is a known architectural limitation that the team has acknowledged — expect improvement in later releases, but it is a real constraint today.
The Behavioral Assertion Judge Model Is Opaque
The judge model that evaluates behavioral assertions is not user-configurable as of the current release. You cannot swap in a different model, tune its evaluation criteria, or inspect its internal reasoning when it produces a surprising result. For teams in regulated industries where audit trails are required for evaluation decisions, this is a blocker. The BridgeSpace team has indicated that a self-hosted judge deployment option is on the roadmap, but it is not available today.
Pricing Is Not Indexed to Scale
BridgeSpace charges per Canvas seat and per Harness Runner execution minute. For small teams running moderate eval volumes, this is competitive. For teams running continuous integration pipelines that execute eval suites on every commit, the Runner execution costs can compound quickly. Model the cost trajectory carefully before adopting it as a CI component.
Export Portability Needs Work
Exporting a Canvas configuration back to raw framework code (LangGraph, AutoGen) produces working but verbose scaffolding code that is not idiomatic. If you plan to maintain agents both in BridgeSpace and in raw code, the round-trip is awkward. Teams should treat BridgeSpace as the system of record for agent topology, not a pre-processing step before handoff to another tool.
Who Should Be Using BridgeSpace Right Now
Teams building production multi-agent systems who are currently spending significant engineering time managing the seams between evaluation, observability, and debugging tools. The time savings are real and they compound — every sprint where your team spends less time on tooling overhead is a sprint where more cycles go toward actual agent capability.
Organizations standardizing agent development practices across teams. BridgeSpace’s Canvas and Vault create natural artifacts for communicating agent architecture and prompt state across teams. Shared Canvases are more legible than shared Python files for non-specialist stakeholders.
Teams prioritizing regression safety over raw feature velocity. If your agents are in a domain where behavioral regressions have real consequences — customer-facing decisions, financial recommendations, compliance workflows — BridgeSpace’s behavioral assertion layer provides a safety net that custom eval scripts rarely match in coverage.
Not yet recommended for: teams with highly dynamic agent topologies, organizations in regulated industries requiring full eval auditability, or teams running very high-volume CI eval pipelines without careful cost modeling.
The Bigger Architectural Shift BridgeSpace Represents
What BridgeSpace gets right at a conceptual level — beyond any specific feature — is the recognition that agent development is a fundamentally different discipline from software development, and that pretending it is not leads to bad tooling choices.
Traditional software development operates on the assumption of verifiability: you can enumerate the expected behaviors of a function and test them exhaustively. Agent systems are not like this. Their failure modes are semantic, emergent, and context-dependent. A research agent might work perfectly on 99 test cases and hallucinate a citation on the 100th for a reason that has nothing to do with the cases you tested. That is not a testing coverage problem — it is a fundamentally different kind of correctness problem that requires different tooling primitives to address.
BridgeSpace’s behavioral assertions, live execution overlays, and prompt versioning are not features. They are the tooling vocabulary of a new discipline: one that treats agent behavior as a first-class engineering concern rather than an emergent property you hope to observe in production.
Whether BridgeSpace specifically becomes the standard harness for agentic development, or whether its ideas get absorbed and improved upon by the next wave of tools, the direction it points is clearly the right one. The IDE for AI agents cannot look like the IDE for Rails. It has to look something like this.
Bottom Line
BridgeSpace is the most complete agentic development environment available today. Its behavioral assertion layer, live Canvas execution overlay, and unified prompt versioning address the real friction points of building production multi-agent systems in ways that no other single tool currently matches. The limitations are real — dynamic graph support, opaque judge models, and pricing at scale all warrant scrutiny — but they do not change the fundamental assessment: if you are building multi-agent systems professionally, BridgeSpace belongs in your evaluation short list immediately.
Rating: 4.3 / 5.0
Reviewed on BridgeSpace version 0.9.2 (March 2026). Evaluation ran across six weeks using Python-based multi-agent systems on LangGraph and custom harness configurations. All benchmark timings represent medians across five independent runs per task.
Ready to evaluate BridgeSpace for your stack? Check our AI agent framework comparison guide for how BridgeSpace fits alongside LangGraph, AutoGen, and CrewAI in a full production architecture. If you have run your own BridgeSpace benchmarks, we want the data — submit your results and we’ll include them in our ongoing comparison index.