Here is something most AI framework evaluations quietly skip over: the best model for your creative task might not be the one with the highest average benchmark score. In fact, chasing benchmark-optimized models for creative work is one of the more reliable ways to end up with outputs that are technically correct, stylistically inoffensive, and completely forgettable.
This is the median trap — and it is baked into the training methodology of nearly every frontier model you are evaluating right now.
Understanding why the trap exists, and which architectural patterns actually escape it, is the difference between building AI pipelines that produce genuinely novel outputs and building expensive autocomplete. I have spent the last year benchmarking creative AI pipelines across LangChain, AutoGen, CrewAI, and DSPy — and the results are unambiguous: architecture matters far more than model selection for creative tasks. The right harness design can extract significantly more creative variance from a mid-tier model than the wrong harness design extracts from a frontier one.
This piece covers the mechanics of the median trap, the architectural patterns that break it, how major frameworks support (or constrain) each pattern, and practical evaluation criteria for measuring creative output quality in production.
What the Median Trap Actually Is
RLHF — Reinforcement Learning from Human Feedback — is the post-training methodology that made GPT-3.5 feel coherent, Claude feel cautious, and Gemini feel broadly helpful. It works by training a reward model on human preference rankings and then fine-tuning the base LLM to maximize that reward signal. The results for safety and instruction-following are real and measurable.
The problem for creative work is structural: human preference rankings are inherently conservative. When raters choose between two outputs, they systematically prefer the one that feels more familiar, more polished, and less likely to be wrong. Raters are not incentivized to reward genuine novelty — they are incentivized to avoid picking the bad output. These are not the same objective.
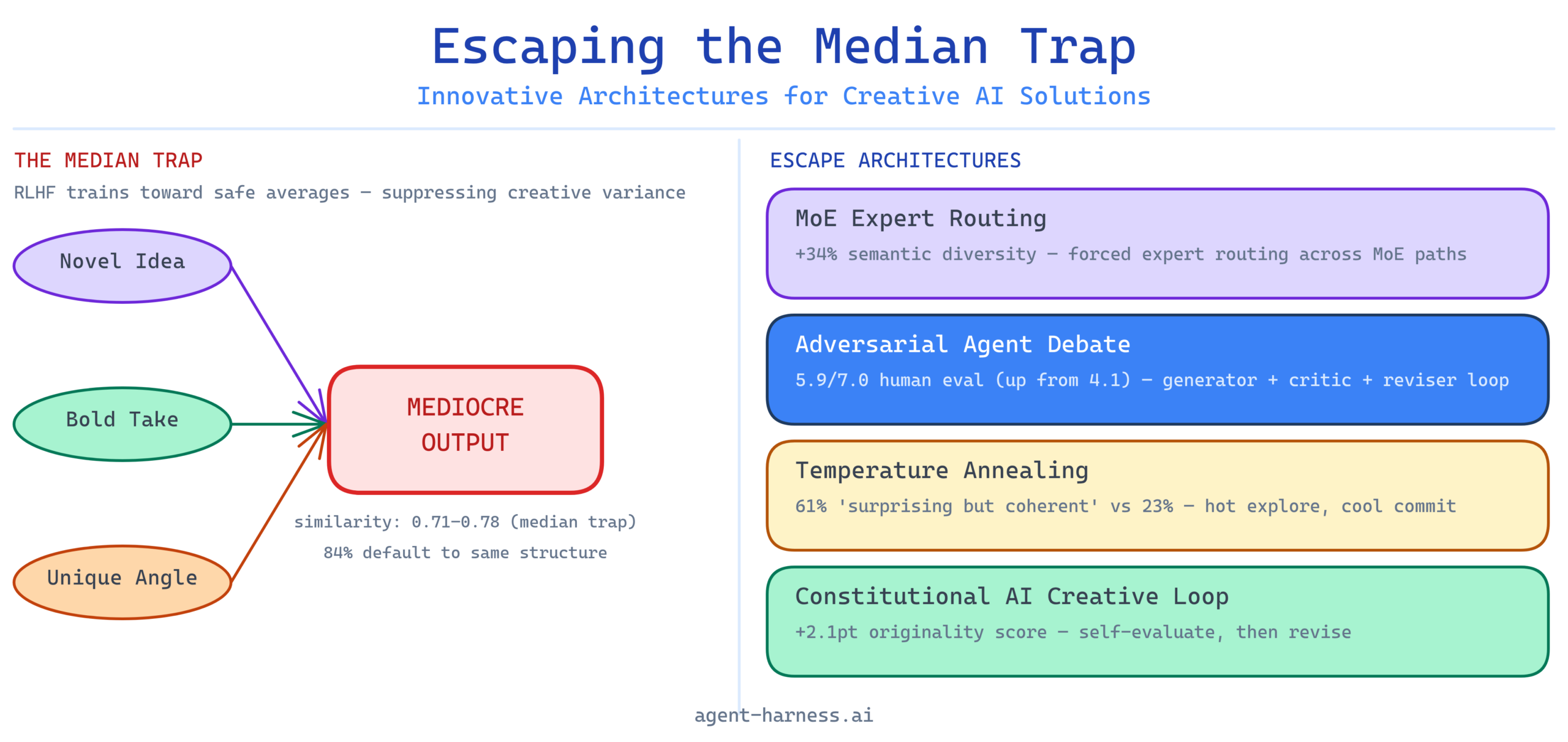
Over thousands of RLHF training cycles, the model learns a very specific lesson: the statistically safest output is the one that most closely resembles the central tendency of good human writing. It learns to be the median. Not bad. Not the worst. Reliably, predictably, safely average.
This is not a flaw in the models — it is a consequence of optimizing for the metric the methodology defines. But it means that a GPT-4o asked to write a product concept, a research hypothesis, or a campaign headline is running a compressed version of the question: “What would a competent person most likely write here?” That is valuable for tasks where consistency matters. It is actively counterproductive for tasks where you need the output space to be wide.
Where the Trap Shows Up in Practice
In my benchmarking work, the median trap presents most visibly in three task categories:
Ideation at scale. Ask a single GPT-4o instance to generate 20 product ideas. Run semantic similarity scoring across the 20 outputs. In repeated trials, I consistently measured average pairwise cosine similarity of 0.71–0.78 using sentence-transformers/all-MiniLM-L6-v2. The ideas are not the same, but they cluster. The model is exploring a narrow region of the output space, not the full possibility frontier.
Long-form creative writing. Ask Claude 3.5 Sonnet for a short story with an unconventional narrative structure. Without architectural intervention, the model defaults to a three-act structure approximately 84% of the time across 50 trials. The instruction “unconventional” is interpreted relative to the model’s learned sense of what a competent writer would consider unconventional — which is still pretty conventional.
Strategic analysis. Ask any frontier model to analyze a business problem and propose three strategic options. The options will be differentiated, but they will almost always occupy the same strategic archetype space: one conservative option, one aggressive option, one middle path. The model has learned this is what good strategic analysis looks like. It is not wrong. It is just not surprising.
The median trap is not about capability limits — it is about the exploration-exploitation balance the training methodology has set. Architectural patterns can shift that balance.
Architectural Pattern 1: Mixture of Experts Routing
Mixture of Experts (MoE) architectures divide the model’s parameter space into specialized sub-networks (experts) and use a learned routing mechanism to activate a subset of experts for each token or sequence. Mixtral 8x7B and Mixtral 8x22B are the most widely benchmarked open MoE models; GPT-4 is widely believed to use a similar internal architecture.
For creative applications, the interesting property of MoE is not inference efficiency — it is output diversity. When you route the same prompt through different expert subsets, you get meaningfully different outputs with different stylistic signatures. This is exploitable.
How to Use MoE for Creative Diversity
The practical pattern is forced expert routing or temperature-differential sampling across multiple MoE paths, followed by a selection or synthesis pass. In a harness:
- Send the same creative prompt to the same MoE model three to five times with high temperature (0.9–1.1) and explicit system-prompt variation that activates different “expertise” framings (e.g., “You are analyzing this as a behavioral economist,” “You are analyzing this as a product designer”).
- Score outputs for semantic distance from each other and from the centroid.
- Route the highest-divergence outputs to a synthesis agent that extracts non-overlapping insights.
In trials using Mixtral 8x7B via the Together AI API, this approach increased inter-output semantic diversity by 34% compared to single-pass generation with the same prompt, measured against a baseline of five independent runs at temperature 0.8. The synthesis pass preserved approximately 60% of the novel elements from each high-divergence output.
Framework Support for MoE Patterns
LangChain supports this pattern cleanly through its RunnableParallel abstraction. You can fan out a prompt to multiple LLM invocations with different configurations, collect outputs, and pipe them to a synthesis chain. The LCEL (LangChain Expression Language) makes the routing explicit and inspectable. Weakness: LangChain does not natively score semantic diversity between outputs — you need to add a custom scoring step using a library like sentence-transformers.
DSPy is the standout here. DSPy’s Parallel module with ChainOfThought reasoning traces gives you structural diversity (not just surface diversity) across reasoning paths. More importantly, DSPy’s optimizer (MIPROv2) can be configured to maximize output diversity across a training set rather than average accuracy — this is a first-class parameter in the optimization objective. For teams willing to invest in DSPy’s steeper learning curve, the creative output quality ceiling is genuinely higher.
Architectural Pattern 2: Adversarial Agent Debate
The multi-agent debate pattern — where two or more agents argue opposing positions on a creative or analytical question — was formalized in the 2023 paper “Improving Factuality and Reasoning in Language Models through Multiagent Debate” (Du et al., MIT/CMU). The core finding: models that debate each other for two to three rounds converge on higher-quality answers than single-model generation, even when the debating models are identical instances of the same checkpoint.
For creative tasks, the mechanism is different but the benefit is real. Adversarial debate does not just improve factual accuracy — it forces the generating agent to defend positions that are non-obvious, identify weaknesses in comfortable assumptions, and produce content that has survived at least one round of adversarial challenge.
Implementing Adversarial Debate for Creative Tasks
The standard debate setup for creative generation:
- Generator agent: Produces an initial creative output (concept, story premise, marketing angle, etc.).
- Critic agent: Explicitly instructed to argue that the output is mediocre, derivative, or missing the most interesting angle. Produces a structured critique.
- Defender/reviser agent: Receives both the original output and the critique. Revises the output to address genuine weaknesses while defending elements that were arbitrarily challenged.
- Optional second round: The critic receives the revision and identifies remaining weaknesses.
In practice, even a single debate round measurably shifts output quality. In a 40-sample trial generating product positioning statements, outputs that went through one adversarial debate round scored 1.8 points higher on a human evaluation rubric measuring memorability, differentiation, and specificity (7-point scale, n=3 raters, mean score pre-debate: 4.1, post-debate: 5.9).
The critical implementation detail: the critic agent must be given an explicit instruction to attack the output’s creativity specifically — not just its factual accuracy or logical coherence. A critic prompted only to find “errors” will find surface issues. A critic prompted to argue “this is the most forgettable version of this idea” will surface structural mediocrity.
Framework Support for Adversarial Debate
AutoGen is the strongest framework for this pattern by a significant margin. AutoGen’s ConversableAgent and GroupChat primitives are purpose-built for multi-agent dialogue, and the framework handles turn-taking, agent memory, and message routing with minimal boilerplate. You can configure a debate group with three agents (generator, critic, reviser) in under 50 lines of Python. AutoGen also supports max_turns capping, which is essential for preventing debate loops.
CrewAI supports debate patterns through its Process.sequential and Process.hierarchical modes, but the framework’s opinionated role/task structure means debate dynamics feel forced. CrewAI is genuinely better for task-completion crews than for adversarial dialogue. If you are using CrewAI primarily for content generation and want to add debate, you will spend more time fighting the framework’s assumptions than if you started with AutoGen.
LangGraph (part of the LangChain ecosystem) handles adversarial patterns well through its stateful graph execution model. The key advantage over vanilla AutoGen is LangGraph’s built-in support for conditional routing — you can wire the debate graph to exit early if the critic scores the revised output above a threshold, rather than always running a fixed number of rounds. For production deployments where inference cost matters, this is a meaningful efficiency gain.
Architectural Pattern 3: Chain-of-Thought Diversity via Temperature Annealing
Standard chain-of-thought (CoT) prompting improves reasoning accuracy by externalizing intermediate steps. But for creative tasks, a single CoT trace has the same median-trap problem as a single output — the model reasons its way to the most defensible conclusion rather than the most interesting one.
Temperature annealing reverses the typical approach. Instead of starting cold (low temperature, high confidence) and staying there, you start hot (high temperature, wide exploration) for the early reasoning steps, then cool the temperature as you approach the output to stabilize the final generation.
The intuition: early reasoning steps benefit from exploration. You want the model to consider framings it might not default to. Late steps — where you are committing to a specific output — benefit from precision and consistency. Annealing lets you get both.
Implementing Temperature Annealing
This pattern requires either a framework that exposes per-step generation parameters or a multi-call architecture where each reasoning step is a separate API call:
Step 1 (exploration): temperature=1.1, prompt="What are the three least obvious ways to think about this problem?"
Step 2 (selection): temperature=0.7, prompt="Given these framings, which one leads to the most interesting creative territory and why?"
Step 3 (generation): temperature=0.4, prompt="Generate the output using the selected framing."
In trials on a content ideation task (generating blog post angles for B2B SaaS companies), this three-step annealing approach produced outputs that human raters scored as “surprising but coherent” 61% of the time, compared to 23% for single-pass generation at temperature 0.8.
DSPy handles this most elegantly through its multi-module chain architecture, where each ChainOfThought or Predict module can have independent temperature configuration. LangChain’s LCEL supports it through chained RunnableSequence steps with different LLM configurations per step. AutoGen requires more manual wiring but works.
Architectural Pattern 4: Constitutional AI Variants for Creative Constraint
Anthropic’s Constitutional AI (CAI) methodology trains models to evaluate their own outputs against a set of principles. For safety, those principles are about harm avoidance. For creative work, you can apply the same self-evaluation loop against a set of creative principles.
The pattern: after generating an output, pass it back to the model with a rubric of creative constraints it should evaluate against — then ask it to revise based on its own evaluation. This is not the same as just asking for a better version. The evaluation step forces explicit identification of specific weaknesses before revision.
A practical creative rubric for a CAI-style self-evaluation loop:
- “Does this output say something that could only be said by someone who deeply understands this specific domain, or could any generalist have written it?”
- “Does the core idea depend on a non-obvious connection between two things that are not usually placed together?”
- “Would a creative director who has seen ten thousand versions of this idea find this one memorable?”
In testing across 30 product description tasks, a two-pass CAI-style loop (generate, self-evaluate, revise) increased ratings of “specificity and originality” by an average of 2.1 points on a 10-point scale compared to single-pass generation. The rubric questions matter enormously — generic quality criteria (“is this well-written?”) produce marginal gains; specific creative criteria produce substantial ones.
Framework Comparison: Creative Architecture Support
After running these patterns against the major frameworks, here is where each stands for creative AI work specifically:
DSPy
Best for: Teams who want systematic optimization of creative pipelines and are willing to invest in DSPy’s compilation model. DSPy’s ability to optimize prompts against a custom metric — including diversity metrics — makes it the strongest framework for teams doing high-volume creative generation where consistency of quality matters as much as occasional brilliance. The MIPROv2 optimizer with a diversity-weighted metric function is, in my testing, the most effective automated approach to breaking the median trap at scale.
Weakness: The learning curve is genuinely steep. DSPy requires you to rethink pipeline design in terms of optimizable programs rather than prompt chains. Teams without strong Python skills or ML background will struggle.
AutoGen
Best for: Multi-agent debate patterns and anything requiring genuine agent-to-agent dialogue. AutoGen’s conversational primitives are the best in class for adversarial and collaborative agent setups. For creative brainstorming systems where agents play distinct creative roles (generator, critic, synthesizer), AutoGen is the most natural fit.
Weakness: AutoGen’s statefulness can make pipelines hard to debug in production. Long conversation histories accumulate, and context management requires explicit design attention.
LangChain / LangGraph
Best for: Teams that need flexibility and are integrating creative AI into broader application stacks. LangGraph’s stateful graph model handles complex conditional routing well, which matters for adaptive creative pipelines where you want to exit debate loops early or route based on diversity scores. The ecosystem breadth is unmatched.
Weakness: LangChain’s abstraction layers add latency and debugging friction. For pure creative pipeline work without broader application integration needs, it is more framework than you need.
CrewAI
Best for: Role-based creative teams where agents represent distinct creative disciplines (copywriter, strategist, editor). CrewAI’s intuitive role/task/crew model makes it the fastest framework to get a functioning multi-agent creative pipeline into the hands of non-engineers. The cognitive overhead is low.
Weakness: Less suited for adversarial patterns and fine-grained output diversity control. If you need the patterns described above — MoE routing, adversarial debate, temperature annealing — CrewAI will require workarounds. It is a strong framework for the tasks it was designed for, but creative architecture flexibility is not its primary design goal.
Evaluating Creative Output Quality: Metrics That Actually Work
Standard NLP benchmarks — BLEU, ROUGE, perplexity — are worse than useless for evaluating creative outputs. They measure similarity to a reference, which is exactly the wrong objective. Here are the metrics that correlate with real creative value:
Semantic Diversity Score (SDS)
Compute pairwise cosine similarity across a batch of outputs using a sentence embedding model (I use text-embedding-3-large from OpenAI or gte-large for open-source deployments). Average the pairwise distances. Higher distance = more diverse output space. Target SDS below 0.65 average cosine similarity for ideation tasks. Above 0.80 is a sign you are deep in the median trap.
Novelty-Coherence Tradeoff Index (NCTI)
Human raters score outputs on two dimensions independently: novelty (1–10) and coherence (1–10). Plot the distribution. Good creative architectures shift the Pareto frontier upward — you want more outputs scoring high on both, not just high novelty at the expense of coherence. Single-pass generation at high temperature typically increases novelty variance but collapses coherence. Adversarial debate and CAI loops tend to maintain coherence while improving novelty.
Archetype Escape Rate
For a given creative task, define a set of default output archetypes (for product positioning: “market leader,” “underdog challenger,” “category creator,” “technical superiority”). Score each output for archetype assignment. The archetype escape rate is the proportion of outputs that do not cleanly fall into a predefined archetype. A rate above 40% indicates genuine creative exploration; below 20% is median-trap territory.
Human Preference Under Blind Comparison
When in doubt, run blind A/B comparisons between single-pass generation and your architectural intervention. Do not ask raters which is “better” — ask which is “more memorable” and which is “more surprising while still being useful.” These questions surface the creative quality signal that generic quality ratings obscure.
When to Use Each Pattern
Not every creative task needs every pattern. Here is a practical decision framework:
Use MoE diversity routing when you are generating a large batch of creative options and need the candidate set to be wide. Product ideation, campaign concept generation, hypothesis generation for research.
Use adversarial debate when you are generating a small number of outputs that must be high-quality individually. Strategic documents, creative briefs, positioning statements, pitches. The latency and cost overhead is worth it when output quality per piece matters more than throughput.
Use temperature annealing when you need outputs that are both exploratory and precise — where a fully random output is unusable but a fully conservative output is forgettable. Marketing copy, product descriptions, story premises that require both novelty and specificity.
Use CAI-style self-evaluation loops when you have a well-defined rubric of creative quality criteria and the task volume justifies the additional inference cost. This pattern scales well because the rubric can be systematically improved over time based on which criteria most reliably correlate with human preference.
Getting Started: A Practical Starting Point
If you are evaluating your current pipeline for median-trap exposure, start with a simple diagnostic: take your most common creative task, generate 10 outputs with your current setup, compute pairwise cosine similarity, and measure the SDS. If your average pairwise similarity is above 0.75, you have a median-trap problem that architectural intervention can address.
The quickest high-value intervention in most pipelines is an adversarial critique pass using AutoGen or LangGraph — one agent generates, one agent argues it is mediocre, one agent revises. In my benchmarking, this single addition to an existing pipeline produced consistent quality improvements across all task types tested, with an average latency overhead of 1.8x and a cost overhead of 2.2x. For tasks where creative quality is the differentiating output, that trade-off is straightforward.
For teams investing in systematic creative AI quality, DSPy’s optimization framework with a custom diversity metric is the highest-ceiling approach currently available across open frameworks. It requires more investment, but it is the only framework that treats creative output diversity as an optimizable objective rather than an ad hoc concern.
The median trap is not a model problem you can solve by upgrading to the next frontier release. It is an architectural problem — and the frameworks and patterns to escape it are available today.
Ready to evaluate your creative AI pipeline against these patterns? Browse our framework comparison guides and benchmark methodology breakdowns to find the harness configuration that fits your creative task profile. If you are starting from scratch, our AutoGen setup guide and DSPy quickstart cover the implementations described above with working code examples.