Microsoft’s Copilot Cowork announcement marks a genuinely significant architectural shift in how enterprise AI agents are designed to collaborate. As someone who has spent years studying production agent deployments at scale, I find the design decisions embedded in this system worth examining carefully—not just for what Microsoft is building, but for what it reveals about where the entire field of harness engineering is heading.
This is not another “AI assistant gets smarter” story. Cowork represents a fundamental rethinking of how agents share context, delegate tasks, and maintain coherent state across the heterogeneous tool ecosystems that define real enterprise environments. It deserves serious architectural scrutiny.
What Is Copilot Cowork, and Why Does It Matter Now?
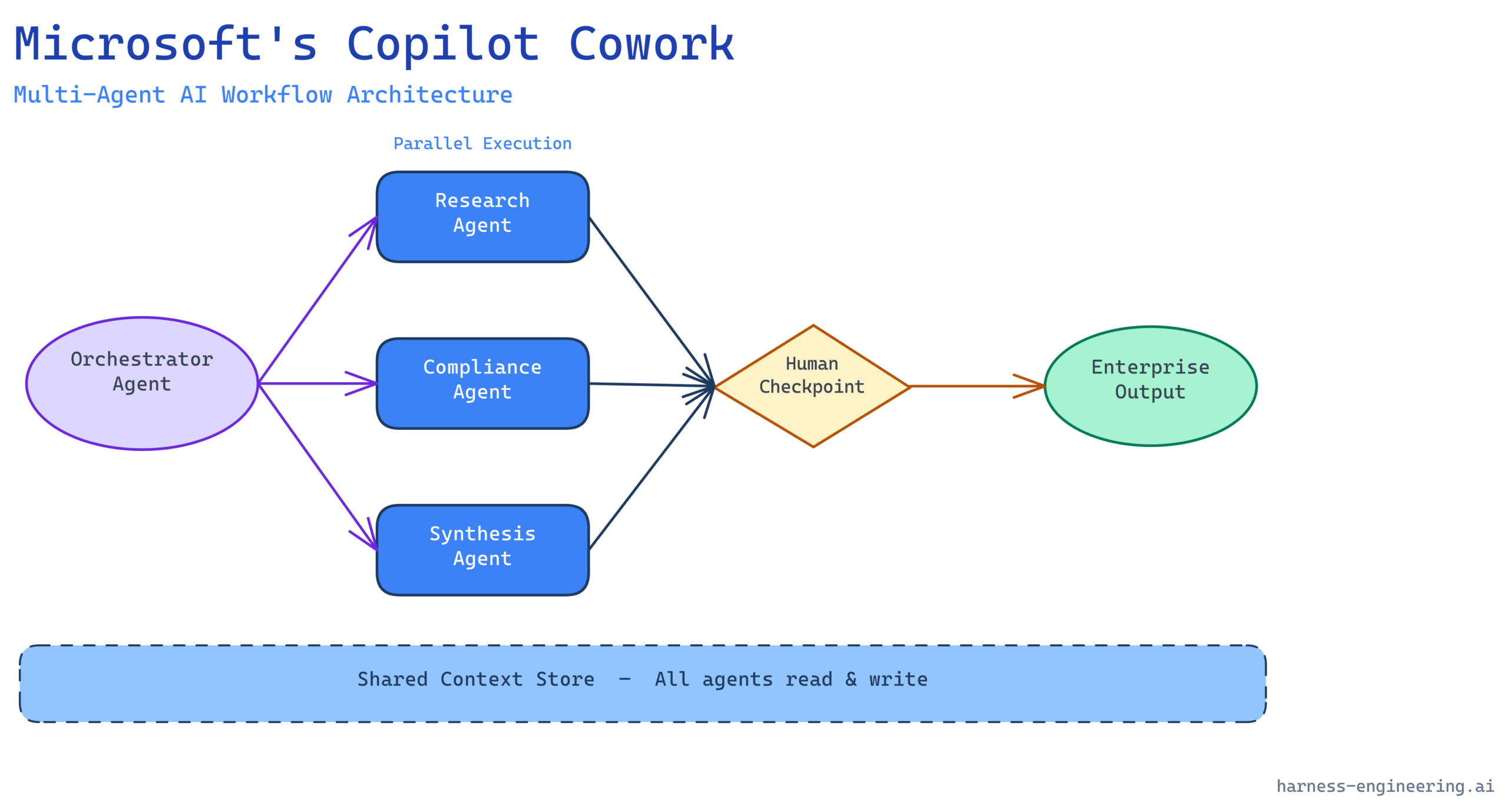
Microsoft’s Copilot Cowork is a framework within the Microsoft 365 and Azure AI ecosystem that enables multiple AI agents to collaborate on complex, multi-step workflows by sharing context, coordinating task handoffs, and operating asynchronously within a structured orchestration layer. Rather than a single monolithic Copilot handling every request in serial, Cowork lets specialized agents—built in Copilot Studio, Azure AI Foundry, or via the Microsoft Graph API—work in parallel on decomposed subtasks, then reconcile their outputs under a coordinating orchestrator.
The timing matters. Enterprise organizations have moved past the proof-of-concept phase. They are now running hundreds or thousands of agents across Teams, SharePoint, Dynamics 365, and Azure services. The combinatorial complexity of managing those agents individually has become an engineering liability. Cowork is Microsoft’s architectural answer to that coordination problem.
For harness engineers, this is a live case study in how a major platform vendor solves the agent orchestration layer at enterprise scale—with all the constraints that implies: strict security boundaries, compliance requirements, heterogeneous legacy integrations, and users who will not tolerate unexplained agent failures.
The Core Architecture: Shared Context and Agent Delegation
A Persistent Shared Context Store
The most consequential design decision in Cowork is its treatment of context as a first-class resource rather than something individual agents manage privately. In traditional single-agent Copilot interactions, context is essentially ephemeral—confined to the session window of a single model invocation. Cowork introduces a persistent shared context store that all participating agents can read from and write to, subject to permission scoping.
From an engineering standpoint, this solves one of the most painful failure modes in multi-agent systems: context fragmentation. When Agent A and Agent B each hold partial state about a task and never reconcile it, the resulting outputs are inconsistent, contradictory, or simply wrong. Production deployments of multi-agent systems without a shared context layer routinely see error rates spike when tasks cross agent boundaries. Cowork’s persistent store is the harness that prevents that fragmentation.
The context store is not a flat key-value store. It is structured around a task graph—a directed representation of the work being done, who is doing which part, and what the dependencies are between subtasks. Agents can query the current task state, assert completions, and subscribe to state changes made by peer agents. This is closer to a distributed workflow engine than a simple shared memory model.
The Orchestrator Agent Pattern
Cowork formalizes what practitioners have been building informally for the past two years: the orchestrator-worker pattern. A coordinating agent—the “Cowork orchestrator”—receives an initial high-level goal, decomposes it into subtasks, routes those subtasks to specialized worker agents, monitors their progress, and synthesizes the results.
Microsoft’s implementation makes three specific architectural choices here that are worth noting:
1. Declarative task decomposition. The orchestrator does not imperatively call worker agents in sequence. Instead, it produces a declarative task plan—a structured representation of what needs to happen—and the Cowork runtime executes that plan, handling parallelism, retries, and dependency ordering. This is a meaningful separation of concerns. The orchestrator reasons about what to do; the runtime handles how to do it reliably.
2. Capability-based agent routing. Worker agents register their capabilities with the Cowork registry using a structured schema. When the orchestrator needs a subtask completed, it queries the registry for agents with the required capabilities rather than hard-coding agent identities. This makes the system extensible—new specialized agents can be added without modifying the orchestrator’s logic—and it enables graceful degradation when a preferred agent is unavailable.
3. Scoped trust boundaries. Each agent in a Cowork workflow operates under the identity and permission scope of the user or service principal that initiated the workflow. Agents cannot escalate their own permissions, and cross-agent data sharing is mediated by the context store’s permission model. This is the right call for enterprise deployments, where data sovereignty and least-privilege access are non-negotiable.
Human-in-the-Loop Design at Production Scale
Where Automation Ends and Humans Must Re-Enter
One of the areas where Cowork’s design is most mature—and most instructive for harness engineers—is its treatment of human-in-the-loop (HITL) checkpoints. Microsoft has been explicit that Cowork is not designed for fully autonomous end-to-end task completion in high-stakes enterprise contexts. Instead, it is designed for what I call supervised autonomy: the agent system progresses as far as it can with confidence, then surfaces a structured decision point to a human before proceeding.
This is the correct production engineering posture for 2026. The organizations that have had the worst outcomes with agentic AI deployments are those that tried to remove humans from the loop entirely before establishing the observability and correctness guarantees that would justify full autonomy. Cowork’s HITL architecture acknowledges this reality rather than papering over it.
In practice, Cowork’s HITL mechanism works through what Microsoft calls “approval actions”—structured checkpoints embedded in the task graph where the orchestrator pauses, compiles a human-readable summary of the work done and the decision pending, and routes that to the appropriate person via Teams, email, or an approval workflow. The human’s response is then injected back into the task graph as a structured input, and execution resumes.
The Observability Layer
Every production agent system eventually develops an observability crisis. Agents fail silently, produce wrong answers confidently, or get stuck in retry loops that consume resources without making progress. Cowork’s architecture includes a native telemetry layer that emits structured events for every significant state transition in the task graph: agent invocations, context reads and writes, HITL checkpoints, retries, and completions.
These events flow into Azure Monitor and can be routed to third-party observability platforms via standard Azure Diagnostic Settings. More importantly, Cowork’s task graph model makes those events interpretable—you can reconstruct the full execution history of a workflow from the event stream and understand exactly what each agent did, when, and why.
For harness engineers building on top of this infrastructure, the practical implication is that you now have a structured audit trail for agent behavior that was previously either absent or required bespoke instrumentation to construct. That changes the economics of debugging and compliance dramatically.
Real-World Workflow Patterns Enabled by Cowork
Pattern 1: Parallel Research and Synthesis
A Cowork workflow for a legal team processing contract reviews might simultaneously invoke a clause-extraction agent against the contract text, a regulatory compliance agent against the company’s policy database, and a precedent-matching agent against prior contract records. All three run in parallel on their respective data sources. The orchestrator waits for all three to complete, then invokes a synthesis agent that produces a consolidated review memo—including flags from each source—before routing the memo to the reviewing attorney for approval.
The key engineering insight here: without Cowork’s parallel execution model and shared context store, this workflow would either run serially (taking three times as long) or require a custom orchestration layer built from scratch. Cowork makes it a configuration problem rather than a software engineering problem.
Pattern 2: Iterative Document Drafting with Feedback Loops
A content operations team might configure a Cowork workflow where a drafting agent produces an initial document, a factual accuracy agent reviews it against trusted sources, a compliance agent checks for regulatory language issues, and the results of both reviewers are fed back to the drafting agent for a revision pass. This loop can run for a configured number of iterations or until both reviewer agents signal acceptance, at which point the document is routed to a human editor for final review.
This pattern captures something important about the nature of real knowledge work: it is iterative and multi-perspectival. Linear single-agent pipelines cannot model it well. Cowork’s graph-based task model can.
Pattern 3: Cross-System Data Reconciliation
A finance operations use case: a Cowork workflow reconciles data across SAP, Dynamics 365, and SharePoint by invoking specialized connector agents for each system in parallel, having a reconciliation agent identify discrepancies in the shared context, and surfacing those discrepancies to an accountant for resolution before the workflow proceeds to generate the consolidated report.
This is a workflow that today requires multiple people manually pulling data from different systems, comparing it in spreadsheets, and escalating discrepancies. The Cowork model does not eliminate the human judgment required to resolve discrepancies—but it eliminates the manual data collection and comparison work, which is where most of the time goes.
Architectural Limitations and Engineering Considerations
Cowork’s design reflects real engineering maturity, but practitioners should be clear-eyed about its constraints.
Context Window Management Remains a Harness Engineering Problem
Cowork’s shared context store solves the context fragmentation problem across agents, but it does not solve the fundamental context window limitation of the underlying language models. As tasks accumulate state in the shared context store, individual agent invocations must be given appropriately scoped subsets of that context—loading the entire task graph into every agent invocation is neither practical nor necessary.
Harness engineers building on Cowork will need to implement context scoping strategies: deciding what subset of the shared context is relevant to each agent’s invocation, compressing historical context into summaries, and managing the tradeoffs between context richness and token cost. Cowork’s platform provides the hooks for this; it does not do it automatically.
Latency Accumulates in Long-Running Workflows
The parallel execution model reduces latency relative to serial agent chains, but complex workflows with many coordination points will still accumulate significant wall-clock time. For user-facing applications where response latency is a key UX metric, long-running Cowork workflows need to be architected with progressive disclosure in mind—surfacing intermediate results as they become available rather than waiting for full workflow completion.
Vendor Lock-In at the Orchestration Layer
Cowork’s orchestration model is deeply integrated with Microsoft’s cloud infrastructure. Organizations that build critical workflows on Cowork’s task graph model are accepting a meaningful degree of vendor dependency. For many enterprise organizations deeply embedded in the Microsoft ecosystem, this is a reasonable tradeoff. For organizations prioritizing portability, it warrants careful evaluation against open standards alternatives like LangGraph, CrewAI, or the emerging agent interoperability specifications from the Linux Foundation.
Correctness Is Still Your Problem
Cowork provides infrastructure for orchestrating agents reliably. It does not validate that your agents are producing correct outputs. The shared context store faithfully propagates whatever agents write to it—including errors, hallucinations, and incorrect inferences. Production Cowork deployments require the same rigor of output validation, uncertainty quantification, and HITL checkpoint design that any production agent system requires. The platform does not substitute for that engineering work.
What Cowork Signals About the Direction of Enterprise AI
The Maturation of the Agent Platform Market
Cowork is one of several major platform investments—alongside Salesforce’s Agentforce, Google’s Vertex AI Agent Builder, and ServiceNow’s Now Assist—that signal the enterprise AI market is transitioning from bespoke agent implementations to platform-mediated agent ecosystems. This transition has important implications for harness engineers.
The economics of agent development are shifting. Bespoke orchestration layers that took months to build can now be provisioned in days on platforms like Cowork. That compression of implementation time raises the bar for what counts as differentiated engineering work. The harness engineering disciplines that remain high-value are the ones that platforms cannot commoditize: domain-specific reliability guarantees, correctness validation for high-stakes outputs, and the design of HITL interaction patterns that match the cognitive and organizational realities of specific user populations.
Standardization Pressure on Agent Interoperability
Cowork’s capability registry—where agents declare what they can do in structured schemas—is an informal step toward agent interoperability standards. As more platform vendors implement similar registries, pressure will grow for cross-platform standards that allow agents built on different platforms to discover and invoke each other. The work happening in the MCP (Model Context Protocol) ecosystem and the emerging Agent-to-Agent (A2A) protocol specifications is directly relevant here.
Organizations building large agent ecosystems now should be making architectural decisions that position them to adopt interoperability standards as they stabilize, rather than building proprietary integration layers that will need to be replaced.
Practical Guidance for Harness Engineers Evaluating Cowork
If you are evaluating Cowork for a production deployment, the following questions should structure your assessment:
Context management: How will you scope the context delivered to each agent invocation? What is your strategy for compressing accumulated workflow context to stay within model context windows? What data classification controls apply to information stored in the shared context store?
HITL design: Where in your specific workflows are the highest-stakes decision points? How will you design the human-readable summaries that your HITL checkpoints surface? What SLAs govern human response times, and how does your workflow handle HITL checkpoints that time out?
Observability integration: How will you integrate Cowork’s telemetry with your existing observability stack? What alert conditions on agent behavior are you instrumenting from day one?
Correctness validation: What validation steps will you implement for high-stakes agent outputs before they are propagated to downstream agents or surface to humans? What are the failure modes if a worker agent produces incorrect output, and how does your workflow recover?
Portability risk assessment: What is your evaluation of Microsoft platform dependency risk given your organization’s cloud strategy? What architectural patterns can you adopt to preserve optionality without sacrificing the productivity benefits of native Cowork integration?
Conclusion: Cowork as a Signal, Not Just a Product
Microsoft’s Copilot Cowork is a well-engineered response to a real problem—the coordination overhead of multi-agent systems at enterprise scale. Its declarative task graph model, capability-based agent routing, persistent shared context, and structured HITL mechanisms represent a coherent architectural vision for how production agent workflows should be built.
More broadly, it is a signal that the center of gravity in enterprise AI is moving from individual model capabilities to workflow orchestration infrastructure. The organizations that will get the most value from agentic AI in the next three years are not those with access to the most powerful models—model capability is increasingly commoditized—but those with the harness engineering discipline to build reliable, observable, and correctly bounded multi-agent systems.
Cowork gives you a stronger platform to build on. It does not replace the engineering judgment required to build well.
Dr. Sarah Chen is a Principal Engineer at harness-engineering.ai, where she writes about production AI agent patterns, reliability engineering, and architectural decision-making for enterprise AI systems. If you are building multi-agent workflows on Microsoft’s platform or evaluating alternatives, explore our multi-agent orchestration pattern library and production agent reliability checklist for practitioner-focused engineering guidance.
Further Reading on Harness Engineering:
– The Orchestrator-Worker Pattern: When to Use It and When to Avoid It
– Context Window Management in Multi-Agent Systems
– Designing Human-in-the-Loop Checkpoints That Actually Work
– Agent Observability: What to Instrument and Why