Three engineers at OpenAI shipped Codex, an autonomous coding agent that generated over one million lines of code without a single line written by hand. The model behind it was impressive. But the model was not the breakthrough. The harness engineering was.
Codex ran inside a sandboxed environment with structured tool access, verification loops that checked every code change against test suites, and a context engineering pipeline that fed the agent precisely what it needed at each step. Swap the underlying model for a competitor, and output quality shifts by 10-15%. Change the harness design, and you change whether the system works at all.
The harness is the 80% factor.
This is harness engineering: the emerging discipline of building the infrastructure layer that makes AI agents reliable in production. Not the model. Not the prompt. The orchestration, verification, and operational infrastructure that wraps the model and determines whether an agent delivers consistent results or collapses under real-world conditions.
If you are building agent-powered products or deploying agents into enterprise workflows, harness engineering is the discipline you need to understand. This guide covers what it is, why agents fail without it, the five core components every harness needs, architecture patterns that work, and how to get started.

Listen to This Article
Prefer listening? Two AI hosts discuss what harness engineering is, why it matters more than the model, and how companies like Vercel and LangChain are applying it — in a 24-minute deep dive.
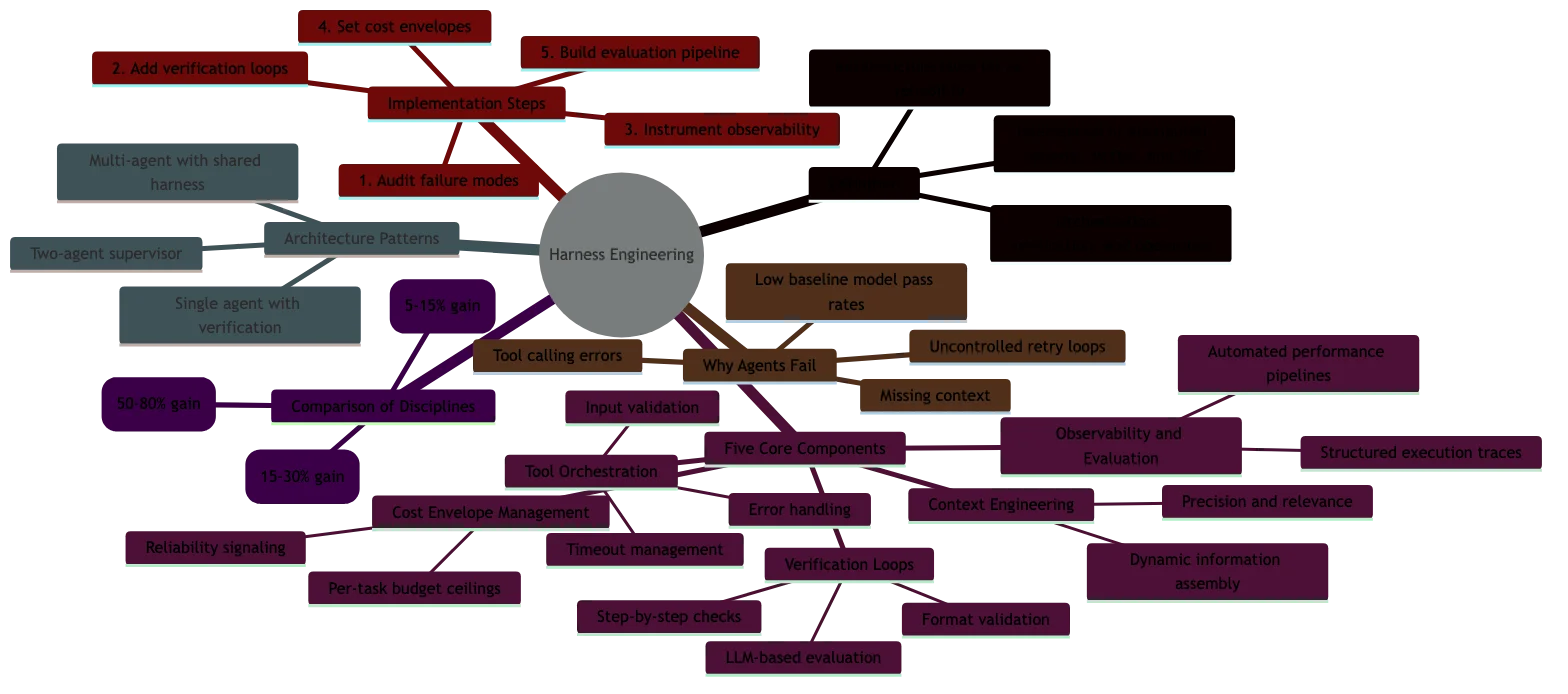
Interactive Concept Map
Click any node to expand or collapse. Use the controls to zoom, fit to view, or go fullscreen.
What is harness engineering?
Harness engineering is the discipline of designing, building, and operating the infrastructure that constrains, informs, verifies, and corrects AI agents in production. The harness encompasses everything between the user’s request and the agent’s final output that is not the language model itself: context assembly, tool orchestration, verification loops, cost controls, and observability instrumentation.The term originates from horse tack, the physical harness that directs a powerful animal’s energy toward useful work without letting it run wild. Anthropic popularized the analogy in their documentation on building effective agents. But the concept extends far beyond coding agents, where most current discussion focuses.
Any agent operating in production needs a harness. A customer support agent needs context engineering to pull relevant account data and conversation history. A research agent needs tool orchestration to coordinate between search APIs, document parsers, and synthesis steps. A data processing agent needs cost envelope management to prevent a retry loop from burning through thousands of dollars in API calls overnight.
Harness engineering sits at the intersection of distributed systems engineering, ML operations, and software reliability engineering. It borrows patterns from all three: circuit breakers from distributed systems, evaluation pipelines from MLOps, observability from SRE. It adapts them for the unique challenges of non-deterministic, multi-step, tool-using systems.
The scope is broad because the failure surface is broad. An agent can fail at context assembly, at tool use, at verification, or at cost control. It can receive wrong information, too much information, or missing information. It can call the wrong tool, call the right tool incorrectly, or fail to handle tool errors. The harness addresses all of these failure points.
Why agents fail without a harness
The APEX-Agents benchmark tells a stark story. This is where the absence of harness engineering becomes measurable. When researchers tested frontier models on professional-grade software engineering tasks, the kind of work companies actually want agents to do, the best models achieved a 24% pass rate on their first attempt. Not 74%. Not 54%. Twenty-four percent.
The models are capable. The infrastructure around them is not.
Most agent failures in production are not model failures. They are harness failures. Here is a pattern that plays out repeatedly: a team deploys an agent that performs well in testing, pushes it to production, and watches it fail on 15-20% of tasks. Their first instinct is to refine the prompt or upgrade the model.
They spend weeks on prompt iterations, drive the failure rate down a few percentage points, and declare progress. Meanwhile, the root cause is a tool integration that silently swallows errors.
Tool calling fails 3-15% of the time in production, even in well-engineered systems. APIs return 500 errors. Responses arrive with missing fields. Timeouts fire during high-latency periods. Without a harness that catches these failures, the agent proceeds with corrupted or incomplete data. The error compounds through every subsequent step.
Consider what happens without cost controls. A document processing agent runs reliably for three weeks. One night, an upstream data source starts returning malformed responses. The agent’s retry policy correctly identifies the bad data and attempts to re-fetch, 340 times over six hours. Each retry consumes a full context window of tokens for the re-planning step. By morning, the bill is $2,400. The usual daily spend is $180.
The verification loop worked perfectly. The cost envelope did not exist.
These are not edge cases. They are the default outcome when teams invest in model quality but not in harness quality. The gap between a demo agent and a production agent is not a model gap. It is a harness gap.
A verification loop, a structured check that validates each step’s output before proceeding, can move task completion rates from 83% to 96% without changing the model or the prompt. The infrastructure matters more than the intelligence.
The five core components of an agent harness
Every production-grade agent harness shares five components. Most teams build two or three of them. The ones that skip the others pay for it in production incidents, runaway costs, and debugging sessions that take days instead of hours.
1. Context engineering
Context engineering is what the agent knows at each step. This goes beyond the initial prompt. It includes dynamically assembled information from databases, APIs, conversation history, file systems, and domain-specific knowledge bases.
The challenge is precision. Too little context and the agent lacks the information to complete the task. Too much context and the agent drowns in irrelevant data, exhausting the context window and degrading output quality.
Effective context engineering means assembling exactly what the agent needs for each specific step. Not dumping everything in and hoping the model figures it out.
Vercel demonstrated this when they reduced their agent’s available tools from 15 to two. Accuracy went from 80% to 100%. Token consumption dropped 37%. Speed improved 3.5x. Less was dramatically more.
2. Tool orchestration
Tool orchestration is what the agent can do: the external systems it interacts with, how it interacts with them, and what happens when those interactions fail.
This is more than wiring up API calls. It includes input validation (is the agent calling the tool with the right parameters?), output parsing (did the tool return usable data?), error handling (what happens when the tool is unavailable or returns garbage?), and timeout management (how long do we wait before declaring failure?).
The tools themselves shape agent behavior. Fewer, well-designed tools consistently outperform many loosely defined ones. Each tool adds a decision point where the agent can make a wrong choice. Wrong tool choices compound across multi-step tasks.
3. Verification loops
Verification loops check the agent’s work at each step before allowing it to proceed. This is the single highest-ROI component of any agent harness.
At the simplest level, a verification loop checks that a tool call returned the expected data format with the required fields. At a more sophisticated level, it uses a second LLM call to evaluate whether the output makes sense given the task context.
The implementation cost is 50-150ms of additional latency per step for schema-based verification, or one additional LLM call for semantic verification. The payoff is disproportionate.
Without verification, silent failures propagate through the entire task chain. With verification, failures are caught at the step where they occur and can be retried, rerouted, or escalated. This is the difference between a system that silently produces bad output and one that fails loudly and recovers gracefully.
4. Cost envelope management
A cost envelope is a per-task budget ceiling that the harness enforces regardless of what the agent or retry policy wants to do. Before each LLM call, the harness checks cumulative token spend against the budget. If the next call would exceed the ceiling, the harness terminates the task with a structured failure response.
Most teams skip this component until they get their first surprise bill.
The counterintuitive insight: cost envelopes are not only financial controls. They are reliability signals. A task that hits its cost ceiling is behaving abnormally, usually because of an underlying failure like a bad upstream response, a context drift problem, or a tool integration error.
Manus demonstrated the financial impact by achieving a 10x cost reduction through KV-cache optimization and intelligent context management. Cost engineering is harness engineering.
5. Observability and evaluation
Observability means structured execution traces that capture what the agent did, why it did it, and what happened at each step. Evaluation means an automated pipeline that continuously measures agent performance against defined criteria.
Without observability, debugging agent failures is guesswork. A task failed, but which step failed? What was the context at that step? What tool was called? What did the tool return? Without structured traces, answering these questions requires reconstructing the agent’s execution path from scattered logs.
Without evaluation, you discover failures through user complaints. A production evaluation pipeline runs representative tasks on a regular cadence, measures task completion rates and output quality, and alerts when performance degrades. This turns agent reliability from a reactive firefight into a proactive engineering practice.
Harness engineering vs. prompt engineering vs. context engineering
These three disciplines are related but distinct. Conflating them leads to misallocated engineering effort, usually too much time on prompts and too little on infrastructure.
| Dimension | Prompt Engineering | Context Engineering | Harness Engineering |
|---|---|---|---|
| Scope | The instruction text sent to the model | All information assembled for the model at each step | The entire infrastructure wrapping the model |
| Focus | What you ask the model to do | What the model knows when it acts | How the system constrains, verifies, and corrects the model |
| Includes | System prompts, few-shot examples, instruction formatting | Dynamic context retrieval, memory management, token budgeting | Context engineering + tool orchestration + verification + cost control + observability |
| Impact on reliability | 5-15% improvement range | 15-30% improvement range | 50-80% improvement range |
| Failure it addresses | Model misunderstands the task | Model lacks necessary information | System-level failures: tool errors, cost overruns, silent degradation |
Prompt engineering is a subset of context engineering. Context engineering is a subset of harness engineering. You cannot prompt your way to 99.9% reliability. The prompt is one input to the system. The harness is the system.
A team spending three weeks refining prompts to move from 85% to 88% task completion would get more from two days building a verification loop, which would take them to 96%. This is not an argument against good prompts. It is an argument for proportional engineering investment.
Architecture patterns for agent harnesses
Harness engineering uses three patterns that cover most production agent deployments, at increasing levels of complexity. Start with the simplest pattern that meets your requirements.
Pattern 1: Single agent with verification loop
The simplest production-grade pattern. One agent, one verification step between each action.
def run_agent_with_verification(task, tools, cost_ceiling):
context = assemble_context(task)
total_cost = 0
while not task.is_complete():
# Agent decides next action
action = agent.plan(context, tools)
# Execute the action
result = execute_tool(action)
# Verify the result before proceeding
verification = verify_output(result, action.expected_schema)
if not verification.passed:
if verification.retry_recommended:
result = retry_with_backoff(action, max_retries=3)
else:
return TaskResult(status="failed", reason=verification.reason)
# Check cost envelope
total_cost += result.tokens_used
if total_cost > cost_ceiling:
return TaskResult(status="budget_exceeded", partial=context)
# Update context for next step
context = update_context(context, result)
return TaskResult(status="complete", output=context.final_output)This pattern handles 80% of production use cases. The verification loop catches tool failures. The cost envelope prevents runaways. The context update keeps the agent focused. Most teams should start here.
Pattern 2: Two-agent supervisor
Anthropic’s recommended pattern for higher-reliability requirements. A primary agent executes the task. A secondary agent, the supervisor, reviews each step and can override, request revision, or approve.
The supervisor sees the same context as the primary agent plus the primary agent’s output. It evaluates whether the output meets quality criteria before the system accepts it. This adds latency (one additional LLM call per step) and cost (roughly 2x token consumption for verified steps), but it catches semantic errors that schema-based verification misses.
Use this pattern when the cost of bad output exceeds the cost of verification. Financial agents generating reports. Customer-facing agents where errors damage trust. Coding agents modifying production systems.
Pattern 3: Multi-agent with shared harness layer
Multiple specialized agents coordinating through a shared infrastructure layer. The harness provides common services, context management, tool access, verification, cost tracking, and observability, that all agents consume.
This pattern is necessary when a single task requires different capabilities (research, analysis, writing, code generation) that benefit from specialized agents. The shared harness layer prevents each agent from implementing its own verification and cost control, which would lead to inconsistent behavior and duplicated failure modes.
The tradeoff: orchestration complexity increases significantly. Agent coordination failures become a new failure mode. This is where harness engineering becomes most demanding. Do not adopt this pattern unless you have outgrown single-agent with verification.
Real-world results: what harness engineering delivers
The evidence base for harness engineering is growing across companies of different sizes and use cases.
| Company | Harness Investment | Result |
|---|---|---|
| OpenAI (Codex) | Sandboxed environment, verification loops, structured tool access | 1M+ lines of code generated by 3 engineers in 5 months |
| LangChain | Harness engineering improvements to their Terminal Bench agent | Task completion: 52.8% to 66.5% (no model change) |
| Vercel | Tool reduction (15 to 2), context optimization | Accuracy: 80% to 100%, tokens -37%, speed 3.5x |
| Stripe (Minions) | Agent harness for code changes | 1,000+ merged PRs per week via agents |
| Manus | KV-cache optimization, context management | 10x cost reduction |
Two patterns emerge from these results.
First, harness improvements consistently deliver larger gains than model upgrades. LangChain’s 14-percentage-point improvement came from harness engineering alone. The model did not change. Vercel achieved 100% accuracy by reducing tool complexity, not by using a smarter model.
Second, cost and performance improvements often come together. Vercel’s accuracy improvement coincided with a 37% reduction in token consumption. Fewer tools meant fewer wrong decisions, which meant fewer wasted tokens. Manus cut costs 10x through smarter context management.
When the harness is well-engineered, agents use fewer resources to produce better results. These are not cherry-picked successes. They reflect a consistent pattern: the teams investing in harness infrastructure are the ones shipping reliable agents.
How to get started with harness engineering
Start with what you have. If you are running an agent in any form, even a simple LLM-powered workflow, you already have the starting point for harness engineering.
Step 1: Audit your current agent’s failure modes
Run your agent against 50-100 representative tasks and categorize every failure. Where does it break? Tool call errors? Context missing? Hallucinated actions? Wrong tool selection?
This audit tells you which harness component to build first. Most teams discover that 60-70% of failures trace back to two or three root causes. Fix those first.
Step 2: Add verification loops (highest ROI)
Start with schema-based verification after every tool call. Check that the response has the expected fields, the expected types, and non-empty values. This catches the majority of silent tool failures with minimal latency overhead (50-150ms per check).
If you do nothing else from this article, do this. It is the single highest-impact investment in agent reliability.
Step 3: Instrument observability
Add structured execution traces that capture each agent step: what tool was called, what the input was, what the output was, whether verification passed, and how many tokens were consumed.
You cannot improve what you cannot see. Start with a structured log format that captures these fields for every step. Build dashboards later. The raw traces are immediately valuable for debugging.
Step 4: Set cost envelopes
Calculate your median task cost over a representative sample. Set your default cost envelope at 3x the median. Any task exceeding this ceiling is terminated and routed to review.
This takes 30 minutes to implement. It prevents the $2,400 overnight surprise that every team without cost controls eventually experiences. If you need help designing cost envelopes for your specific agent workload, reach out for a production readiness review.
Step 5: Build an evaluation pipeline
Create a set of 20-50 representative test tasks with expected outcomes. Run them on a scheduled cadence: daily for high-volume agents, weekly for low-volume ones. Track task completion rate, output quality scores, and cost per task over time.
This transforms agent reliability from anecdote (“seems to be working fine”) to measurement (“task completion rate dropped from 94% to 87% after Tuesday’s deployment”).
The biggest barrier to harness engineering is not technical. It is cultural. Engineers trained to solve problems through craft, writing better code and designing better algorithms, struggle with the delegation mindset that agent systems require. Harness engineering is not about making the agent smarter. It is about building the infrastructure that makes a capable agent reliable.
Frequently asked questions
What is the difference between an agent harness and an agent framework?
An agent framework (LangChain, CrewAI, AutoGen) provides scaffolding for building agents: base classes, tool abstractions, and orchestration primitives. An agent harness is the complete production infrastructure wrapping your agent, including verification, observability, cost control, evaluation, and error recovery. Frameworks give you a starting point. The harness is what makes it production-grade.
Is harness engineering the same as prompt engineering?
No. Prompt engineering focuses on the instruction text sent to the model. Harness engineering encompasses the entire infrastructure surrounding the model, including context assembly, tool orchestration, verification, cost management, and observability. Prompt engineering is one input to the system. Harness engineering is the system.
Do I need harness engineering for simple chatbots?
A basic Q&A chatbot with no tool use and no multi-step reasoning does not need a full harness. But the moment your system calls external APIs, executes multi-step workflows, or operates without human review of every output, you need at least verification loops and cost controls. Most systems that start as “simple chatbots” do not stay simple.
What skills does a harness engineer need?
Harness engineering draws on distributed systems design, ML operations, software reliability engineering, and traditional backend development. The most important skill is systems thinking: understanding how components interact and where failures propagate. Strong harness engineers think about failure modes before they think about features.
Will harness engineering become obsolete as models improve?
The scope will change, but the discipline will not disappear. Better models will eliminate some failure modes and create new ones at higher abstraction levels. The smartest approach: design harnesses for deletion. Build components that can be removed as models improve, rather than architectures that assume models will always need the same level of control. The infrastructure should get simpler over time, not more complex.
The harness is the product
Harness engineering is not a nice-to-have optimization. It is the discipline that separates demo-quality agents from production-grade systems. The model is a commodity input, capable, powerful, and increasingly interchangeable. The harness is where reliability lives.
Three takeaways to act on:
1. Start with verification loops. They deliver the highest reliability improvement per hour of engineering effort. Schema-based verification after every tool call is the minimum viable harness.
2. Measure before you optimize. Add observability instrumentation and build an evaluation pipeline. You cannot improve agent reliability without knowing where it currently stands and where it breaks.
3. Set cost envelopes from day one. A per-task budget ceiling takes 30 minutes to implement and prevents the runaway cost event that every unprotected agent eventually produces.
The teams shipping reliable agents are not the ones with the best models. They are the ones with the best harnesses. The model swap changes output quality by 10-15%. The harness design is the 80% factor.
If you are building agent-powered systems and want production-tested patterns delivered weekly, subscribe to the harness engineering newsletter. No hype, no fluff: architecture patterns, failure mode analysis, and operational insights from real agent deployments.
5 thoughts on “What Is Harness Engineering? The Discipline That Makes AI Agents Reliable”